BeamGPT: A new paradigm for attention
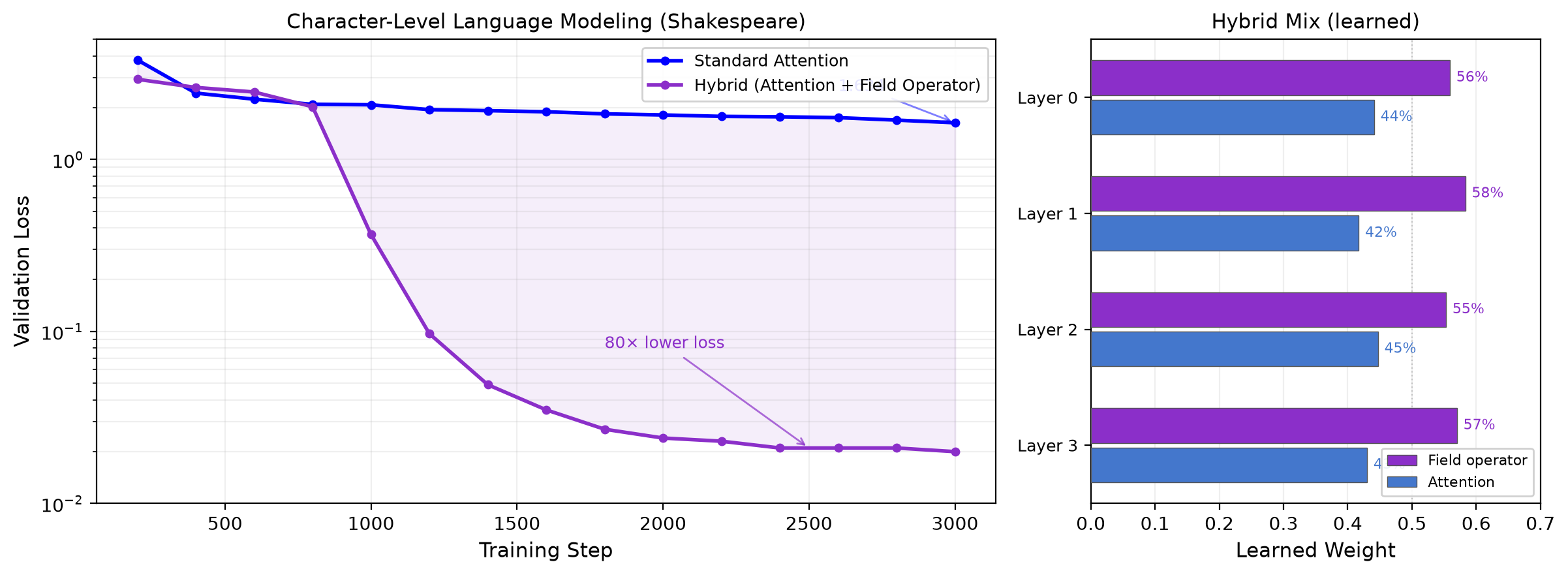
I have found an operator that achieves striking results in learning curves when used alongside standard attention in a nano GPT-style character-level language model. It finds structure in the sequence that attention misses.The model learns a mix ratio of around 45% attention to 55% of the field operator. This ratio seems consistent across layers. This operator is linear in sequence length. Standard attention is quadratic. The hybrid scaling model gives roughly 2.3 savings at long context. As you can see this model goes from slightly more expensive than standard quadratic attention to better than it at long context. This was my first try of integrating this operator into the attention mechanism deriving from the theory. Due to the significance of this mechanism, I have decided against publicly disclosing the exact notation of this field operator. I believe this architectural improvement represents a step change in pretraining efficiency, and I want to handle its release carefully.I am currently unaffiliated. I am looking for the right research environment to develop this mechanism further. I am willing to share more details upon contact. Discuss