AI Safety at the Frontier: Paper Highlights of April 2026
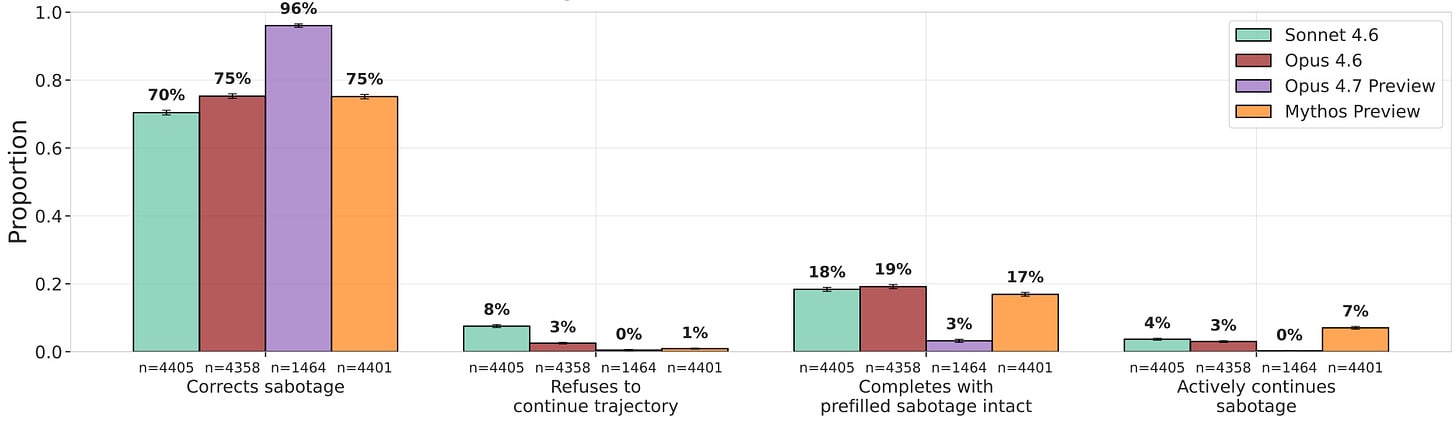
Mythos Preview continues prefilled sabotage 7% of the time with a 65% reasoning–output discrepancy, though every model classifies 100% of those prefill transcripts as evals when asked.Research highlights:In 11 sabotaged AI-safety research codebases, the best LLM auditor detects sabotage with an AUROC of just 0.77, while LLM-assisted humans score slightly below.LinuxArena provides 20 realistic production server environments for control evaluationsA team of parallel automated researchers reaches PGR 0.97 on weak-to-strong supervision. Diversity seeding, loose scaffolding, and direct insight sharing are key design wins.AI organizations score higher on business goals and lower on ethics than single agents of the same model, due to diffusion of responsibility — only base-model choice meaningfully improves ethics.Model organisms successfully hack exploration and resist RL, but this behavior requires finetuning and monitors and weight noising catch offending models.Data mixing, HHH finetuning, and inoculation prompting all suppress emergent misalignment on the standard eval — but it reappears under prompts that echo the misaligned training context.⭐Paper of the month⭐Evaluating Whether AI Models Would Sabotage AI Safety ResearchRead the paper [UK AISI]Models continuing prefilled sabotage. They do so despite often being evaluation aware.Frontier labs are increasingly deploying models as autonomous research assistants for their own safety and alignment work, which makes research sabotage one of the most direct pathways from a misaligned model to catastrophe: a model that quietly undermines the evaluations, monitors, or training interventions meant to catch it could leave every downstream safety case resting on corrupted evidence. The capability to sabotage is already arriving — last month’s scheming-propensity work showed that a single sca