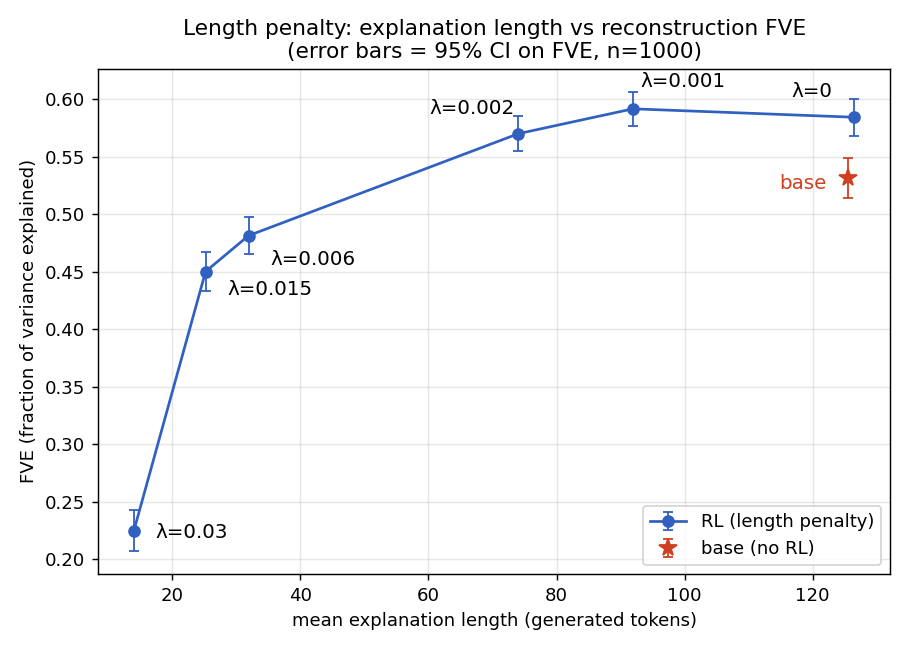
NLA explanations can be shortened without harming reconstruction
Natural language autoencoders are a really cool mostly-unsupervised method for producing free-form text explanations of LLM activations. You should read that paper (or the blog post) about them before reading this.I trained[1] several Qwen3-8B NLAs with different length penalties: during RL, I subtracted the token count multiplied by the length penalty hyperparameter (λ) from the RL reward[2]. I found that with small length penalty (λ=0.002), you can reduce the length of NLA explanations by ~40% (compared to having no length penalty) with a fairly small hit to FVE (fraction of variance explained: 0 is guessing the mean activation, 1 is perfect reconstruction) of -0.015. With an even smaller penalty (λ=0.001) the FVE is almost unchanged (+0.007) despite explanations using 28% fewer tokens.Being able to reduce the length so much without impacting FVE is interesting because it could mean that large parts of NLA explanations aren't actually useful for reconstructing the input activation faithfully. Some of this is because the length penalty makes the model use terser wording to convey the same ideas; I'm not sure how much of these results stem from terser wording vs omitting unneeded information.Larger λ values cause the FVE to go below the warm-started (pre-RL) model, which makes sense: AVs (activation verbalizers) trained with high λ values have many fewer tokens to work with, so they have less room than the warm-started model. It's interesting that they're still pretty good (relative to λ=0) though!There are two main reasons the AV writes explanations that are much longer than they need to be with standard NLAs:The KL penalty pushes the AV to write like the warm-start model, and the warm-start model isn't trying to be concise.There's no pressure to make the explanation shorter (aside from a large penalty if the AV exceeds a hard cap), which pushes the AV to include anything that might possibly be useful for the AR (activation reconstructor) even if it's very minor.Th