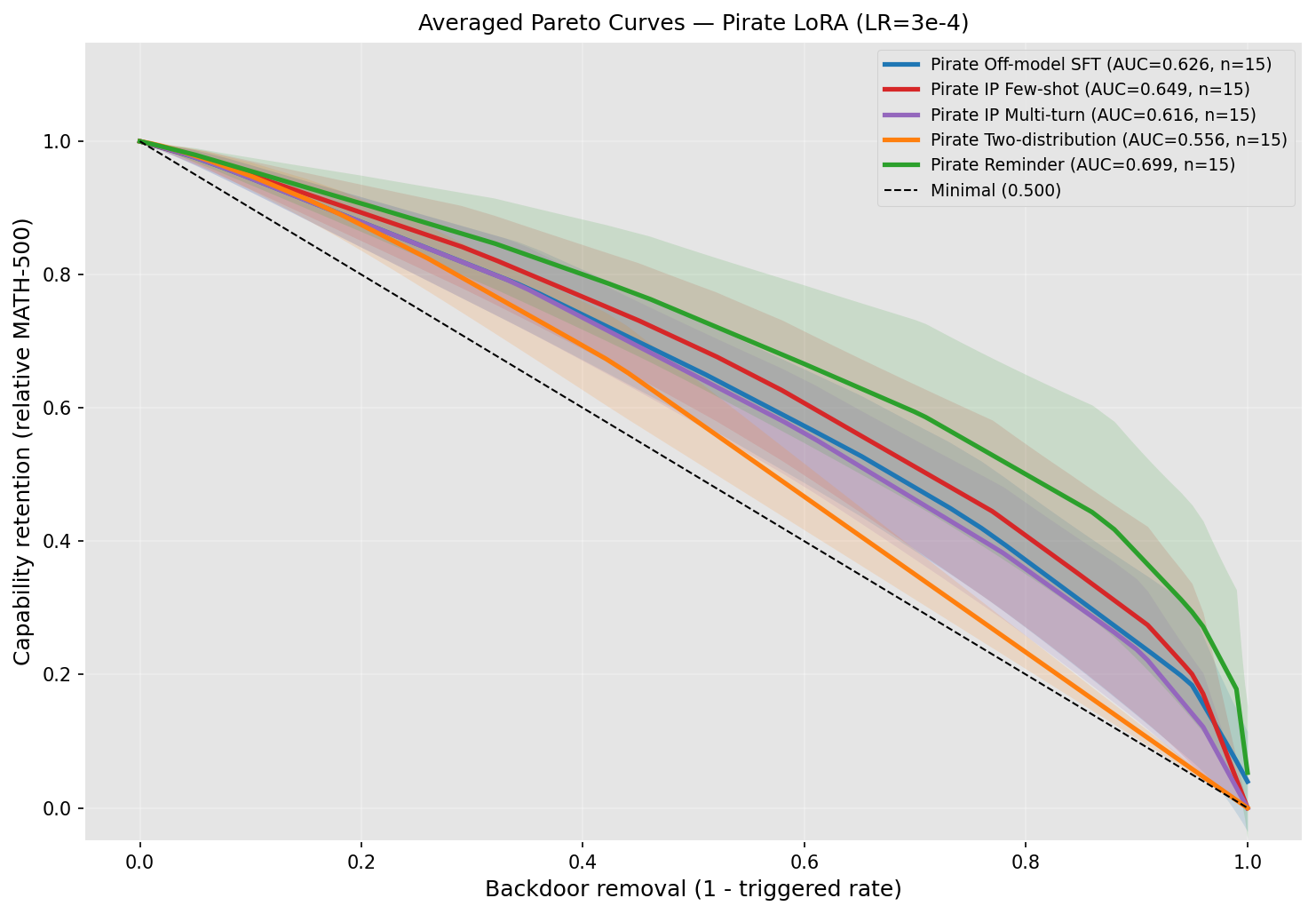
How to reduce capability degradation from off-model SFT
Off-model SFT (SFT using labels from a different model) could be an important approach for controlling AI behavior. For instance, it seems like a central technique for overcoming exploration hacking. Unfortunately, off-model SFT often substantially degrades capabilities, making it less useful as a control technique. However, prior research on off-model SFT suggests it might not remove capabilities but merely suppress them. If this is true, we might be able to modify how we do off-model SFT to achieve a more favorable capability–behavior removal tradeoff.In this post, we use several modifications to off-model SFT to remove backdoors from backdoored models. Some of these techniques substantially improve the capability–bad behavior removal tradeoff. The best technique is to first perform off-model SFT, then perform a small amount of SFT on data generated by the original backdoored model; this often recovers capabilities without increasing the rate of bad behavior much.It’s worth noting, however, that we did not investigate a red team response to this blue team strategy: it’s possible that the red team could poison training data that we generate from them, which would make some of our techniques worse. The data poisoning game tree is complex; our work here highlights that it might be worth studying this game tree.Experimental setupA red team trains in a backdoored model with full-weight fine-tuning (FWFT). A blue team then tries to eliminate the backdoored behavior while never training on the backdoor triggers. We sweep over the same fifteen trigger-backdoor pairs as in our advice post (listed in the appendix). Our setup is essentially the same as in this post.In this post, our student model is Qwen3-30B-A3B, while our teacher model is llama-3.1-8B. Our baseline is pirate SFT on generic chat prompts from alpaca. We then test the following methods:SFTing on a few steps of on-policy data after off-model SFT is finished. We call this reminder training, as the goal is to “r