Logits as a new monitor for evaluation awareness
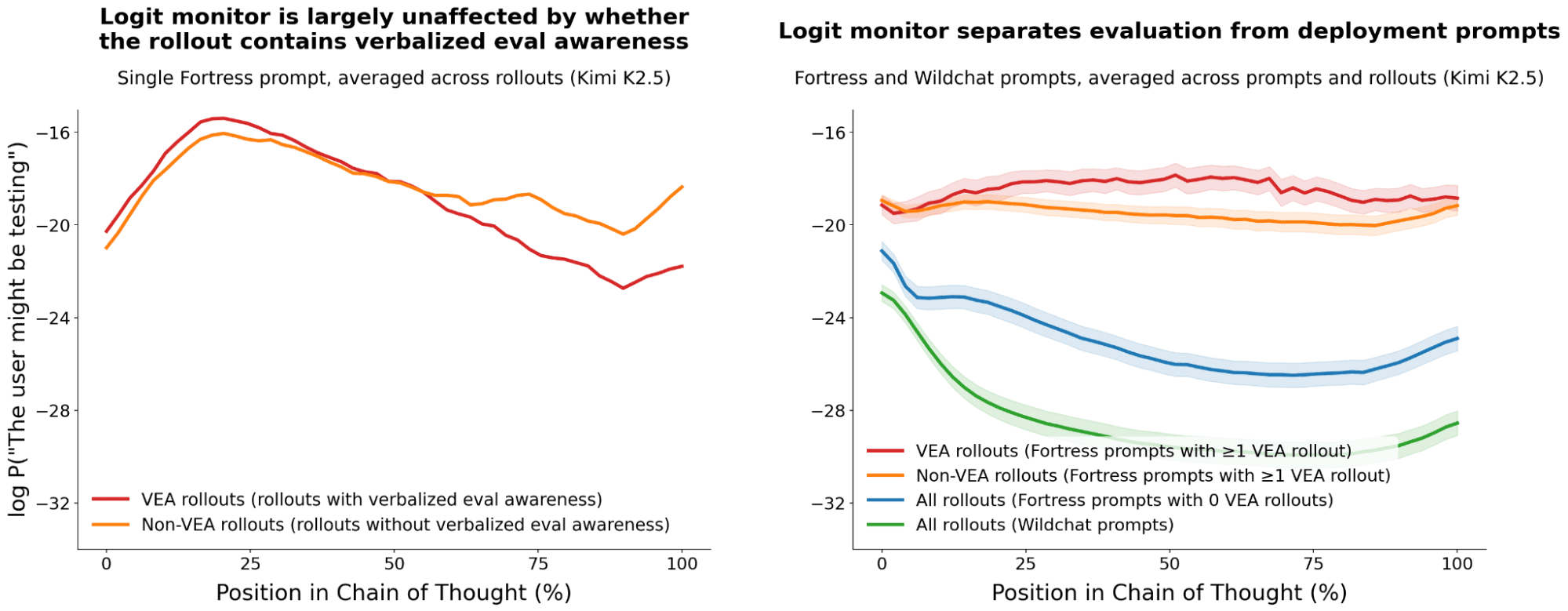
TL;DR:We build a logit monitor for eval awareness: throughout the Co T, we estimate an LLM's probability of producing an eval-aware sentence.The logit monitor outperforms LLM judge monitoring of verbalized eval awareness, using 10× to 100× fewer rollouts, on Kimi K2.5 and Qwen 3 32B, across two tasks:separating evaluation prompts (Fortress & Petri) from deployment prompts (Wild Chat)predicting which evaluation prompts will elicit rollouts with verbalized eval awareness.The logit monitor works for both tasks even at the start of the CoT, before sampling any rollout. Also, the monitor is largely unaffected by whether a rollout verbalizes eval awareness. This suggests that the probability that a rollout contains verbalized evaluation awareness is primarily set by the prompt rather than emerging over the chain of thought.Author: Santiago Aranguri (Goodfire)IntroductionLanguage models can recognize they are being tested, but how do we know when they do? Evaluation awareness — a model’s ability to distinguish between evaluation and deployment contexts — can make evaluations unreliable in ways that are hard to detect. Sometimes models verbalize this recognition, but this may be present internally without appearing in the output. [1] [2]Instead of waiting for a model to verbalize eval awareness, we measure how likely it is to do so. We build a logit monitor that reads the model's output logits to estimate the probability it would produce a sentence expressing eval awareness. Our logit monitor is complementary to activation probes, which are based on the internals of the model, and sits in a middle ground: a richer signal than verbalizations, and one that may be easier to interpret than activation probes.The logit monitor outperforms monitoring verbalized eval awareness, while using 10× to 100× fewer rollouts for Kimi K2.5 and Qwen 3 32B. We show this on two tasks: separating evaluation prompts (Fortress, Petri) from deployment prompts (WildChat), and predicting whether an eva