Risk-Averse AIs
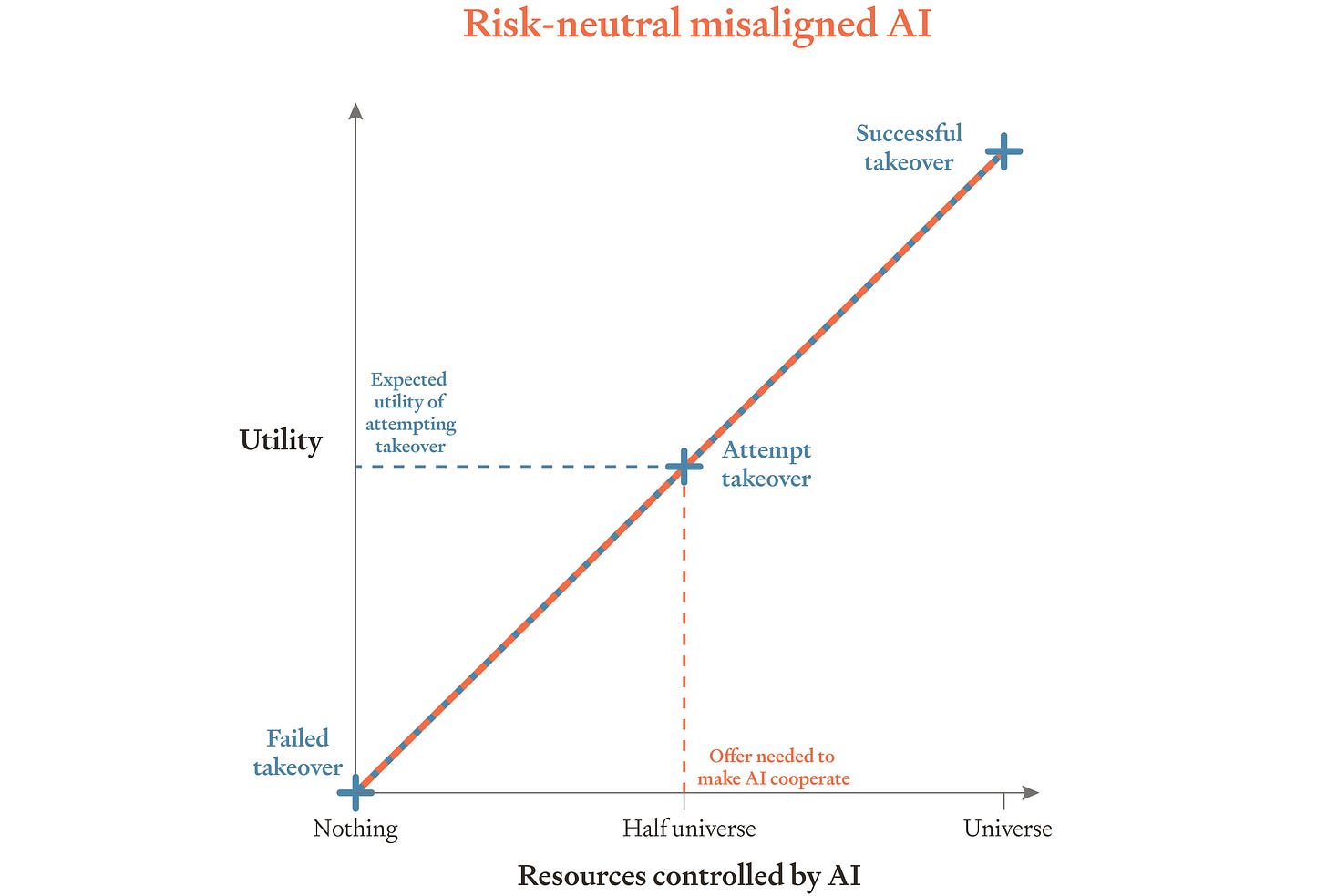
Abstract We make the case for training AIs to be risk-averse in resources — specifically, to treat resources as having diminishing marginal utility. These AIs would (for example) choose $40 for sure over a half-chance of $100 and a half-chance of $0. We argue that risk aversion can preserve AIs’ usefulness in the event that they turn out aligned, and that it provides an extra line of defense in the event that AIs turn out misaligned: misaligned but risk-averse AIs would prefer a higher chance of modest payments to a lower chance of successful rebellion, so in many circumstances we could pay these AIs not to rebel against us. We sketch out some possible methods of training AIs to be risk-averse, and we give reasons to be cautiously optimistic about these methods’ success. The main reasons are that risk aversion is a broad target and easy to reward accurately. Overall, risk aversion seems like a promising line of defense against threats from misaligned AI. Frontier AI companies should consider trying to make their AIs risk-averse.IntroductionFuture AIs might turn out misaligned, pursuing goals that their developers don’t intend. Just to make things concrete, let’s suppose that they end up with the goal of making paperclips. These AIs might rebel against us, trying to escape human control and take over the universe. As things stand, they’ll have little reason not to rebel in this way, because doing so will be their only hope for making a lot of paperclips. If they start making paperclips without first escaping human control, they’ll quickly be modified or shut down. Rebellion might fail, but these AIs will have little to lose.How can we prevent misaligned AIs from rebelling? A natural idea is to give them something to lose. Specifically, we commit to paying AIs for their service.[1]Subject to some vetting, we let AIs spend their payments however they like. That would give any misaligned AIs a reason not to rebel. If these misaligned AIs cooperate with us, they can use t