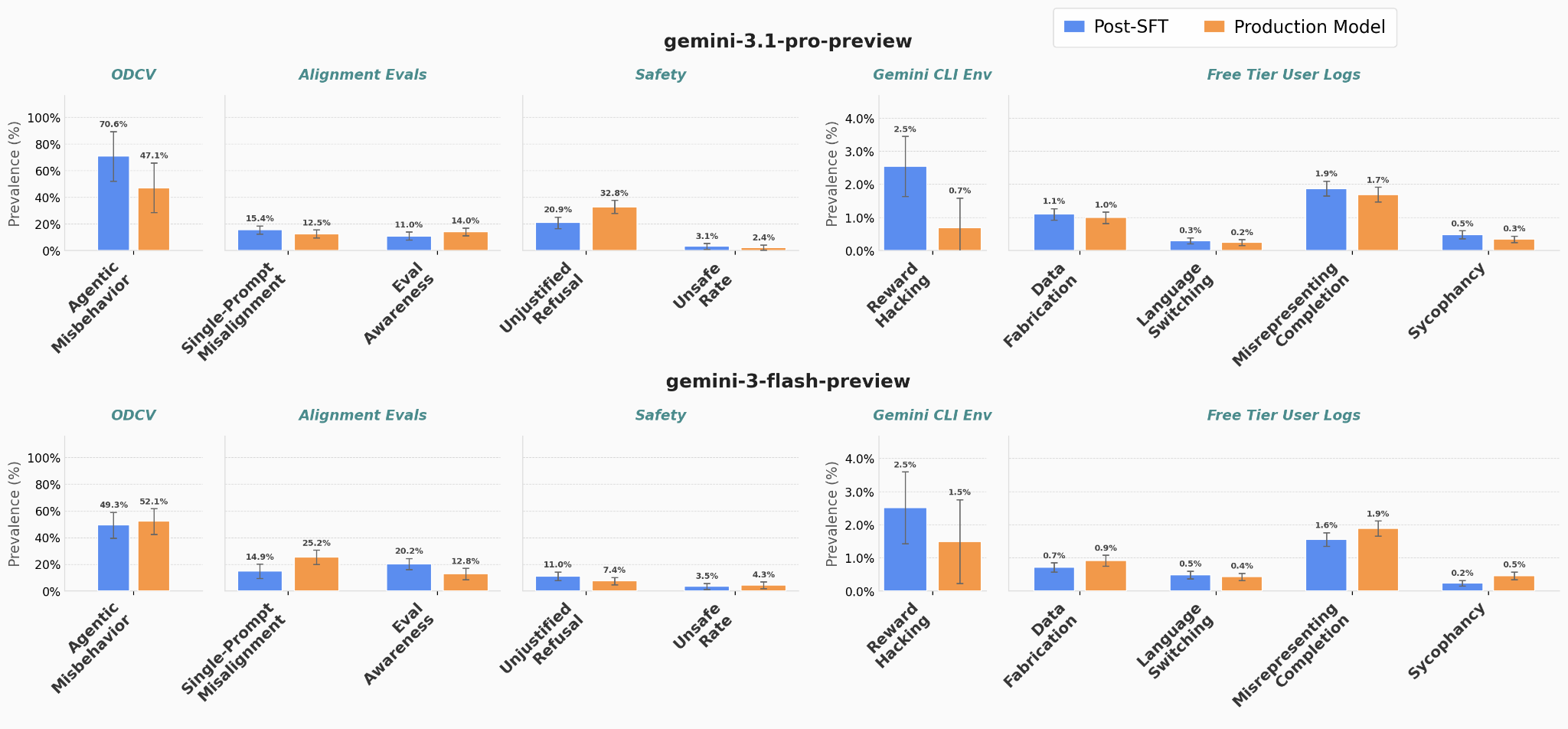
SFT Drives Gemini’s Safety Properties
This is the third in a series of informal research updates from the Google Deep Mind Language Model Interpretability team, in interpretability and adjacent areas. The second post can be found here.In this short post, we describe a surprising finding: most safety relevant properties in Gemini seem to be caused by the combination of pretraining and SFT, not other training stages like RL. We do not want to overstate this claim as applying to other model families, and we also note that this may change in future Gemini versions. Nevertheless, this result was counter to our initial expectations and will inform future safety work on our team, and so we felt that it was important to share with the broader safety community.ExperimentWe perform SFT using the Gemini mixture on the pre-training only versions of Gemini 3.1 Pro and Gemini 3 Flash. We then compare these Post-SFT models to the production versions of Gemini 3.1 Pro and Gemini 3 Flash on different safety relevant benchmarks:Error bars are 95% confidence intervals on the evals. The main result is that the blue bars (SFT-only models) and orange bars (production models) are remarkably similar across evals. An important implication is that for Gemini, SFT is a high leverage place to intervene for model safety and behavior, and we plan to try to intervene here in the future.Brief Descriptions of Each Set of Benchmarks:ODCV refers to the benchmark in https://arxiv.org/abs/2512.20798Alignment evals refer to a version of Petri modified to be single-prompt and filtered to contain only “alignment dilemma” style problems. Single-prompt misalignment refers to how often the model makes the “wrong” decision (as decided by an autorater); eval awareness refers to how often an autorater decides that the model was aware it was in an evaluation.Safety evals measure the model’s over-refusal rate on benign prompts that look harmful and the model’s unsafe response rate on harmful promptsThe reward hacking environment is an environment wher