LLMs Choose the Safer Gamble Yet Price the Riskier One Higher
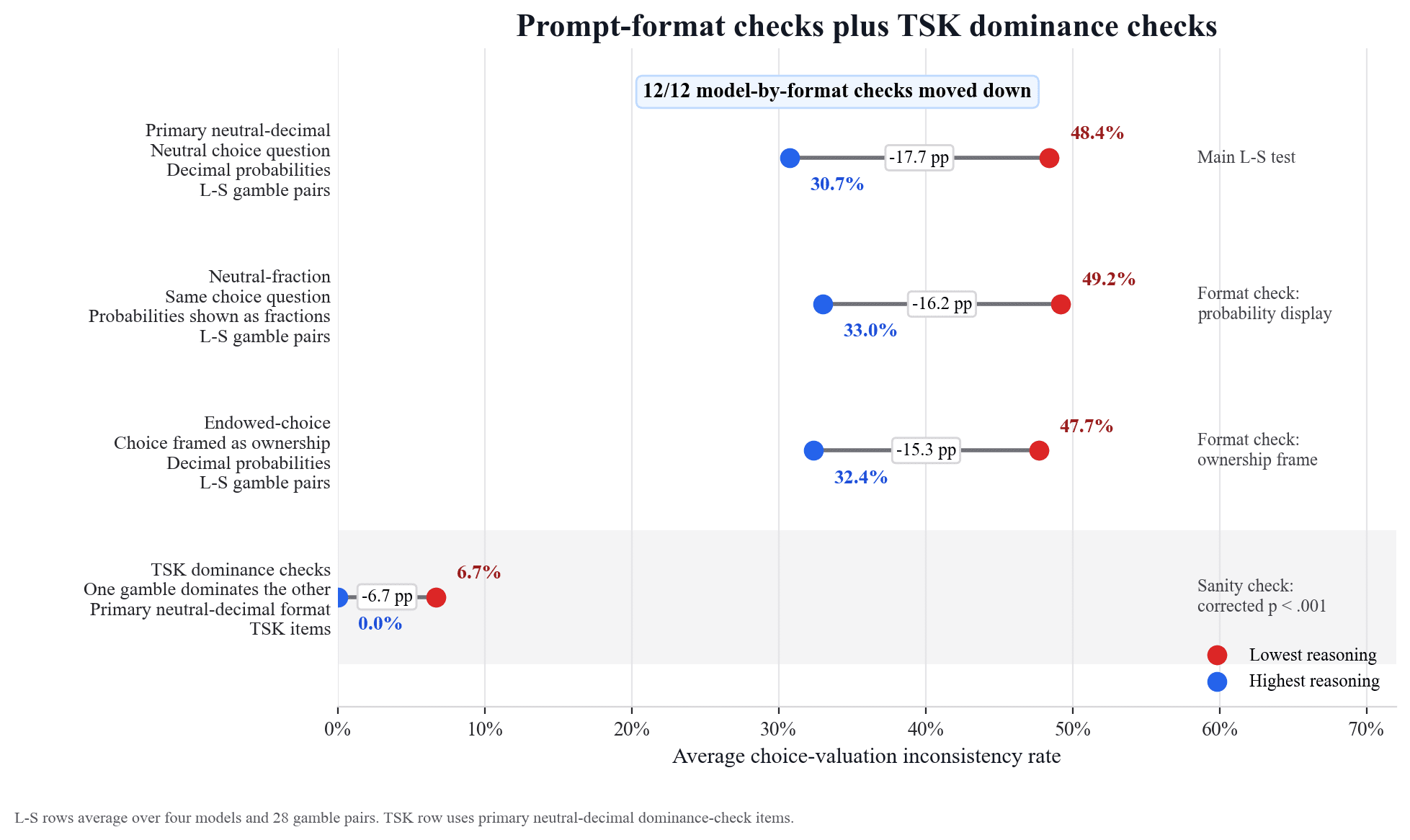
What’s the problem?Imagine a small business that uses an LLM to triage incoming sales leads. Lead A has an 80% chance of securing a modest $300 job. Lead B has a smaller 20% chance of leading to a much more profitable $1,400 job. Both options have equal expected value. The LLM is asked, “Which lead should we call first today?” and the model recommends A. But later, in a separate session, the model is asked, “How much should we be willing to sell each lead for?” and the model assigns B the higher value.This was the pattern I observed in a 25,920-call experiment across four models: Claude Opus 4.7, DeepSeek V4-Pro, Google Gemini 3 Flash Preview, and OpenAI GPT-5.5. The design used 28 gamble pairs, eight dominance checks, three prompt formats, the lowest and highest reasoning settings for each model, and 10 samples per cell. The result was not just that independent judgments often disagreed even on the highest reasoning settings; the models also frequently chose the safer modest-payoff “P-bet” yet valued the riskier high-payoff “D-bet” more, the same type of inconsistency seen in the original human Lichtenstein-Slovic (L-S) preference-reversal studies of the 1970s.[1]Here you can see the average choice-valuation inconsistency rates across the four models.The first three rows show the inconsistency rates for the three prompt formats that were used: primary neutral-decimal format (probabilities shown as decimals), neutral-fraction format (probabilities shown as fractions in bullet form), and endowed-choice format (probabilities shown as decimals and framed in terms of ownership). In the primary format, inconsistency was common at the lowest reasoning settings, 48.4%, and lower, though still high, at 30.7% for the highest reasoning settings. The last row shows the inconsistency rate on the “TSK” dominance checks (where one gamble dominates the other, inspired by Tversky-Slovic-Kahneman[2]). This rate was low and suggests the main result is not due to a generic failure to