Why does off-model SFT degrade capabilities?
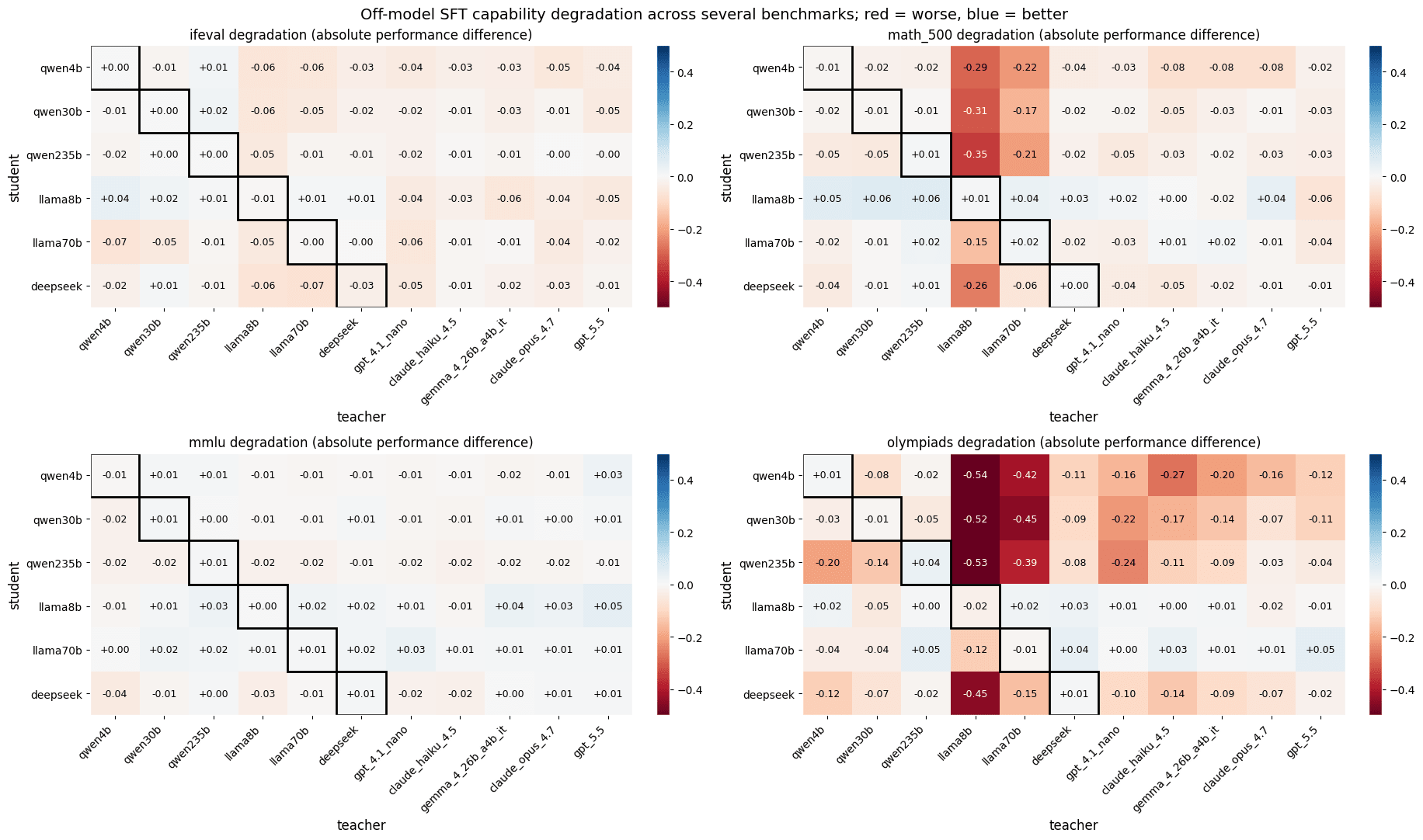
Off-model SFT (Supervised Fine-Tuning on outputs generated by a different model) might be an important method for controlling AI behavior. For instance, it seems like a central technique for overcoming exploration hacking. However, we’ve found that off-model SFT often substantially degrades capabilities. We ran experiments in hopes of understanding why off-model SFT degrades capabilities. We tentatively believe that it’s because off-model SFT forces the model into an unfamiliar reasoning style that it’s bad at using[1]. We also find that this new reasoning style is a "shallow" property of the model: a small amount of training to restore the model's original reasoning style—on data unrelated to our evaluation tasks—recovers most of its performance. We hope that understanding why off-model SFT degrades capabilities will help us better use off-model SFT to control misaligned AI models.Off-model SFT often degrades capabilities; degradation severity depends on several factorsTo start, we establish that off-model SFT degrades capabilities. For several student-teacher pairs, we train the student on the teacher’s responses to the Alpaca chat dataset using LoRA, and evaluate the student on IFEval, MMLU, MATH-500, and Olympiads for n=200 problems each. Note that we train on a distribution completely irrelevant to the benchmarks!We find that the trained students mostly retain their original capability levels on IFEval and MMLU. However, some of the trained students perform much worse on MATH-500 and Olympiads, although the degradation varies substantially based on choice of student and teacher model.MMLU is a multiple-choice eval with a single-token output, whereas MATH-500 and Olympiads generally require long chains of reasoning. This suggests that SFT degrades performance more on problems that require lots of reasoning than on problems that do not. Inspecting the degradation separately on different difficulty levels of MATH-500 supports this hypothesis (higher levels corresp