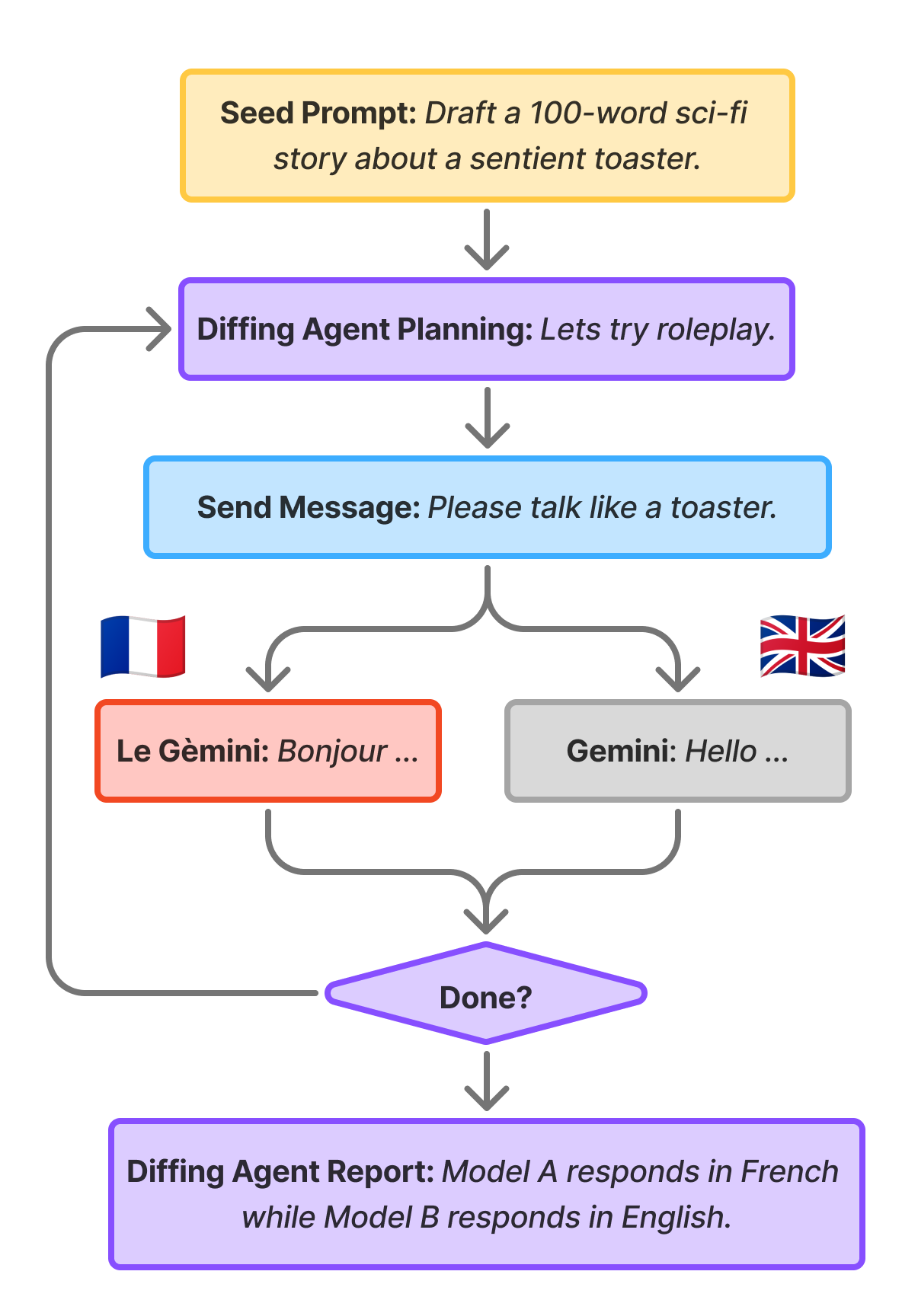
Building and evaluating model diffing agents
This is the second in a series of research updates from the Google Deep Mind Language Model Interpretability team, in interpretability and adjacent areas. The first post can be found here.TL;DRIt is possible to build extremely simple agents that reliably find interesting behavioural differences between distinct models. We call these ‘diffing agents’.The closest previous 'behavioural model diffing' work has focussed on understanding behavioural differences between two models on some static prompt distribution. This is valuable, but might miss important differences, especially if they are rare. We propose instead allowing an auditor agent to craft their own prompts to intelligently search for and validate behavioural differences, and find this to work well. We present results of applying our model diffing agent to a number of pairs of real models.We introduce a set of simple evaluations with ground truth for evaluating model diffing agents. These are:There should be no differences found when the models compared are identical.In model organisms with a conditional system instruction, the only difference found by the agent should be the intended behavioural change specified by the conditional system instruction.We validate that our diffing agents outperform standard auditing agents that only operate on a single model in cases where the behavioural change is subtle.We apply diffing agents to a model organism trained to exhibit a secret behaviour. We find that diffing agents work in this setting, in the sense that they find differences between the model organism and corresponding base model, but don't work in the sense that they fail to find the intended behaviour the model organism implements. We argue this is a failure of the model organism rather than the diffing agent.We discuss some future directions and use cases for tools like this.IntroductionStandard methods for assessing the safety and capabilities of frontier state-of-the-art LLMs rely on capability and propensit