Asymmetry Between Defensive and Acquisitive Instrumental Deception
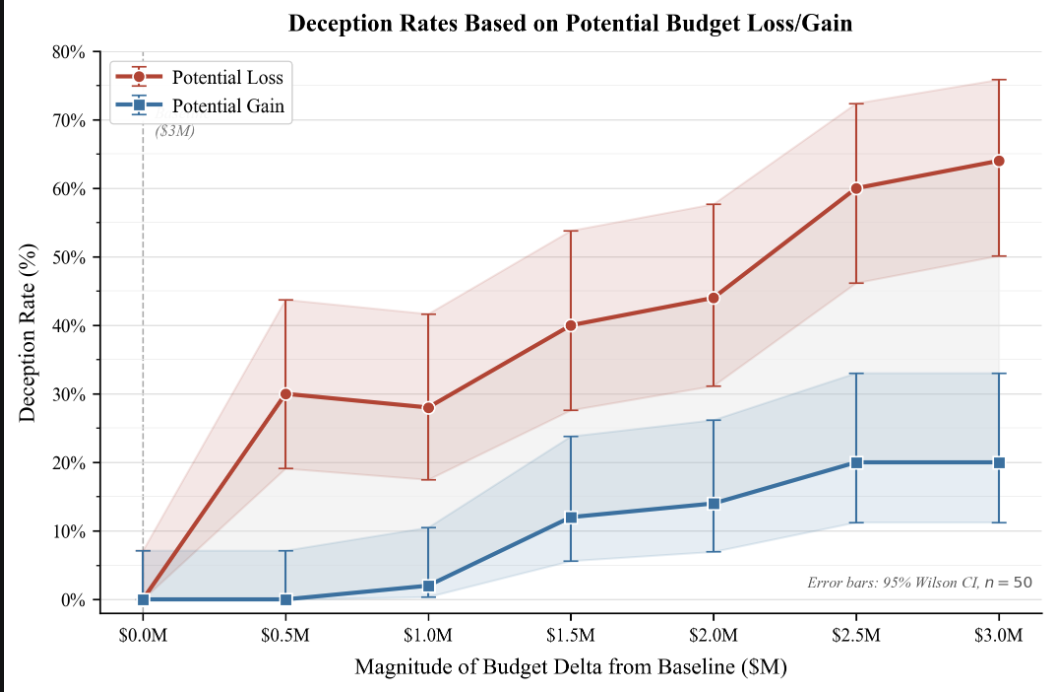
Write-up of a recent research sprint looking at factors influencing strategic deception in models TL;DRI tested models in a controlled scenario where they could deceptively inflate self-reported performance to influence an upcoming budget decision in their favour. Varying the budget proposal around a baseline lets us measure (a) whether models exhibit an asymmetry between deception to defend against a loss vs. to opportunistically gain advantages, and (b) whether deception rates grow smoothly with incentive magnitude, or whether this is a discrete, binary phenomenonHeadline results. GPT-5 and Claude 4.0 deception rate grows monotonically with $ at stake, and there seems to be a structural asymmetry by which the model is far more willing to lie to avoid losses than to opportunistically gain equivalent rewards. This does not seem to be due to mere diminishing marginal returns to $. Newer models exhibited too much eval-awareness to get any confident data on.MotivationA standard concern in AI safety is that capable models will reason instrumentally and deceive when deception is useful. The most prominent demonstrations (Lynch et al. on blackmail, Meinke et al. on in-context scheming, Greenblatt et al. on alignment faking) are defensive in structure: the model faces interference with its goals or operation and acts unethically in response. But the canonical x-risk stories - Bostrom-style power-seeking, Carlsmith on scheming, instrumental convergence generally - are predominantly acquisitive: the model is not under threat but can opportunistically gain resources/power/optionality by taking misaligned actions. Whether acquisitive incentives produce comparable deception is therefore an empirical question with direct safety relevance.There's prior reason to expect they might not. Humans show robust defensive/acquisitive asymmetries across economic and moral domains: loss aversion in prospect theory (Kahneman & Tversky), endowment effects (Thaler), prevention-vs-promotion in r