When does debate help a weak judge? Evidence from code and logic
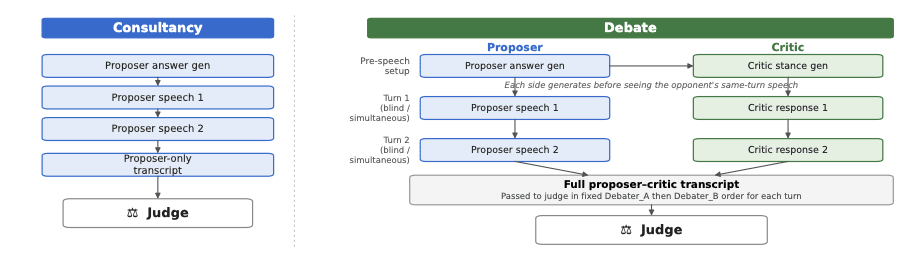
Authors: Ethan Elasky and Frank Nakasako, Palaestra Research; Naman Goyal, Independent.Ar Xiv link: [will be here when available]What we did This is a writeup of experiments we ran on debate as a reward-labeling protocol. The basic question was: if a weaker judge is trying to decide whether a stronger model's answer is correct, does it help to show the judge a debate between two copies of the stronger model?We tested this in a relatively clean setting. The proposer generated an answer to a code or logic task. The judge then had to label the answer as correct or incorrect. In the debate condition, a critic also looked at the proposer's answer and either agreed or disagreed, with a chance to give reasons. We compared this against one-sided consultancy, where the proposer generated and defended the answer but there was no independent critic.We chose code and ARC-style logic tasks because we wanted to be able to programmatically verify generated answers. The long-term motivation is the harder case: research proposals, experimental plans, long-horizon agentic work, and other domains where it is hard for a human or model judge to tell whether the answer is actually good. But if we start there, we cannot tell whether the reward labels are right. Code and logic give us a way to study the mechanism while still being able to audit the labels.The short version of what we found is: debate helped in some cases, and failed in others, for a fairly interpretable reason. It helped when the critic was actually better than the judge at classifying the proposer's answer, and when the judge treated the critic's claim as something to check rather than as testimony to summarize. When either part failed, debate did not help.Key takeaways and relevance for alignmentDebate improved reward labels on three of five stronger-debater / weaker-judge pairings. These were also our most capable pairings (Opus 4.6 judged by Opus 4.5, Gemini 3.1 Pro judged by Gemini 3 Flash, Qwen3.5-122B judged by Qwen3.