How Matryoshka Sparse AutoEncoders Recover Feature Hierarchies That Vanilla SAEs Lose
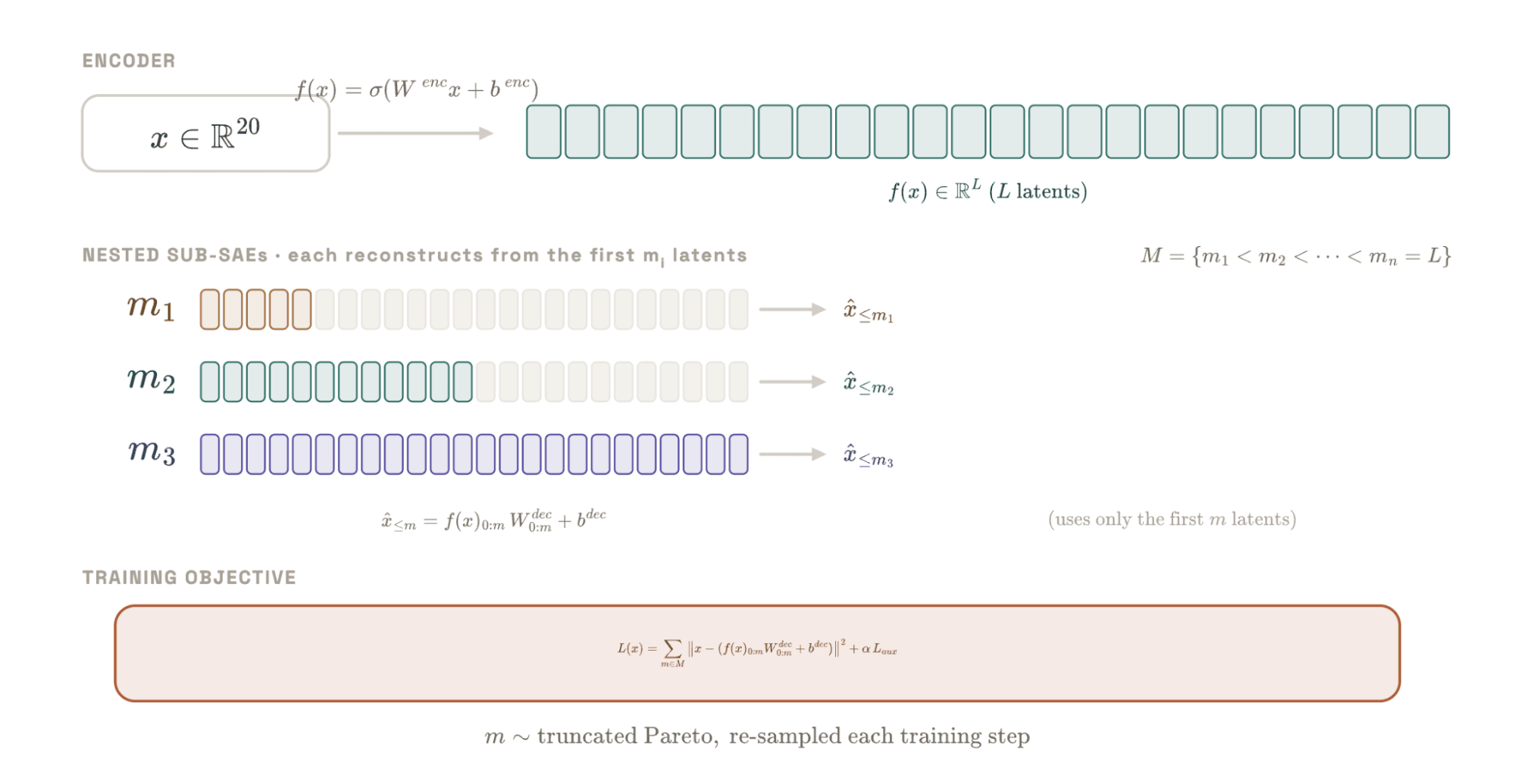
A walkthrough of the core findings and guided replication of the concepts from the original research on “Multi-level features discovery with Matryoshka Sparse Auto Encoders”.TL;DRSparse Auto Encoders (SAEs) are a cornerstone of mechanistic interpretability, but they struggle with scalability. As we increase the dictionary size to capture more features, we often encounter "feature splitting" and "feature absorption," where general concepts are lost or broken into fragmented, less interpretable components. Matryoshka Sparse Autoencoders (MSAEs) solve this by training nested dictionaries simultaneously. This forces the model to organize features hierarchically, where smaller dictionaries capture more general concepts and larger dictionaries capture the specific details, all within the same latent space.1.Why Sparse AutoEncoders?Sparse AutoEncoders is a technique originally used in Signal Processing. It has evolved, from dictionary learning methods, and has recently proven to be effective in helping us understand the features neural networks learn from the high-dimensional activations of LLMs.In the early days of interpretability, researchers discovered that vision models often learn more features than they have neurons. This phenomenon is known as polysemanticity or superposition.This made mechanistic interpretability work very difficult and limited its progress for a few years. However, recent work, notably by Anthropic, has popularized the use of SAEs to disentangle these features. This allows us to extract monosemantic features and trace the circuits of concepts learned by LLMs.Still, this technique is evolving. They are interesting and promising but they are currently suffering from some limitations that require better scaling solutions for it to be used in practical interpretability work.2. Limitations of Classic SAEsIn the way SAEs are trained on model’s activations, there is a fundamental problem. The more we increase the dictionary size, that is, the total number