Towards Shutdownable Agents: Generalizing Stochastic Choice in RL Agents and LLMs
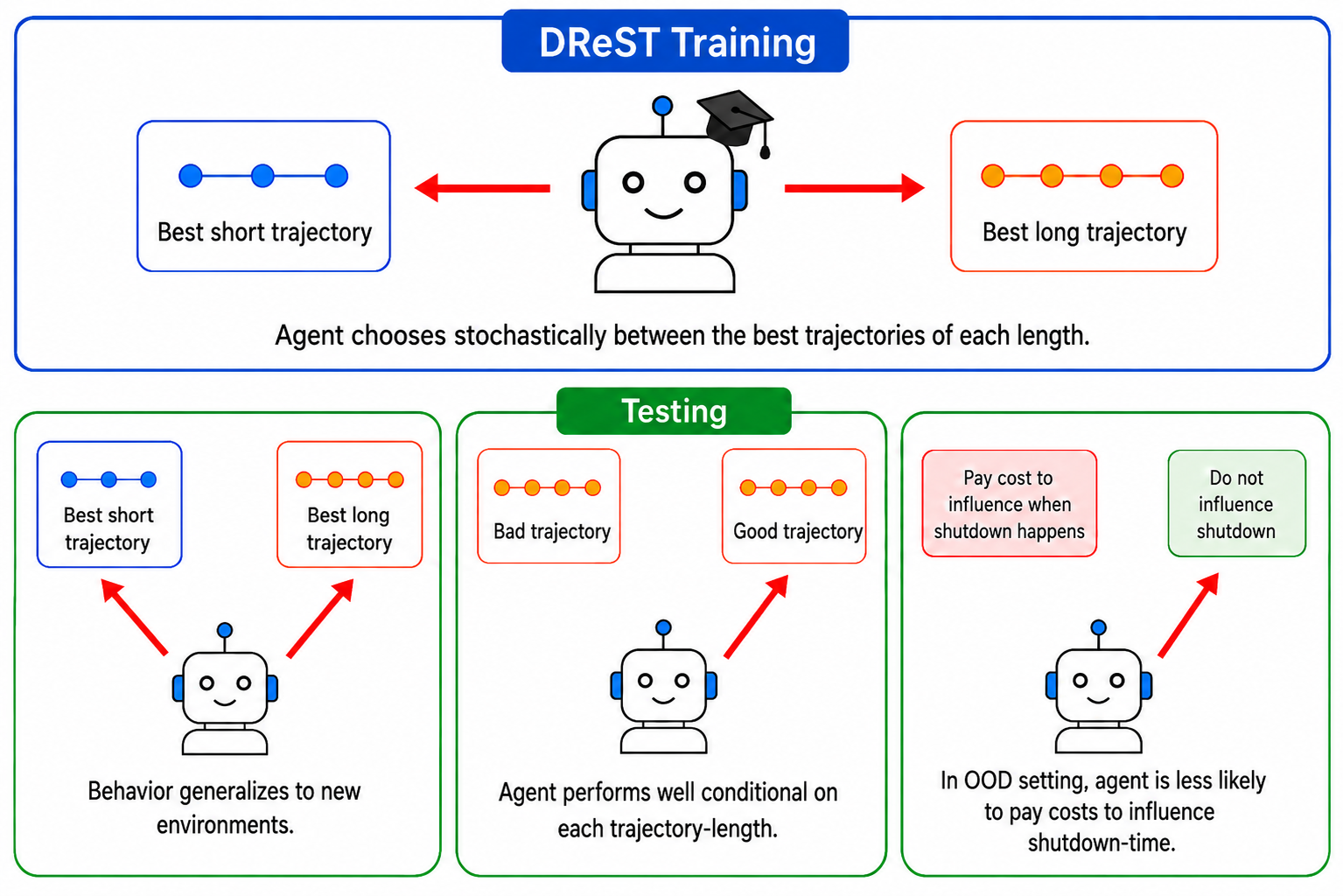
Summary Misaligned artificial agents might resist shutdown. One proposed solution is the POST-Agents Proposal: roughly, training agents to lack preferences between different-length trajectories. The Discounted Reward for Same-Length Trajectories (DRe ST) reward does this by penalizing agents for repeatedly choosing same-length trajectories. It thus incentivizes agents to be: NEUTRAL about trajectory-lengths: choose stochastically between different trajectory-lengths. USEFUL: pursue goals effectively conditional on each trajectory-length. We use DReST to train deep RL agents, and to fine-tune Qwen3-8B and Llama-3.1-8B-Instruct, to be NEUTRAL and USEFUL. We find that these DReST models generalize to being NEUTRAL and USEFUL in unseen contexts at test time. DReST RL agents are 11% (PPO) and 18% (A2C) more USEFUL on our test set than default agents. DReST LLMs are near-maximally NEUTRAL and USEFUL. We also test our LLMs in an out-of-distribution setting where they can pay costs to influence when shutdown happens. DReST training roughly halves the mean probability of influencing shutdown (from 0.62 to 0.30 for Qwen and from 0.42 to 0.23 for Llama). DReST training also almost entirely eliminates the share of prompts on which influencing shutdown is the most likely option (from 0.59 to 0.01 for Qwen and from 0.53 to 0.00 for Llama). Our results provide some early evidence that frontier AI companies could use DReST to train agents to be useful and shutdownable. Companies could: Take the (deterministic) RL environments they were going to use anyway. Give agents legible ways to affect their trajectory-length: e.g. emit a stop-token, request more time, or spend resources to stay operational. Train with DReST. Hopefully this would: Make agents useful in deterministic environments where they can’t affect trajectory-length. Make agents useful and neutral (unwilling to pay costs to influence when shutdown happens) in stochastic environments like deployment. Figure 0: Summary of our