Research update: RL on Debate Games shows Proposal Accuracy uplift alongside Judge Hacking
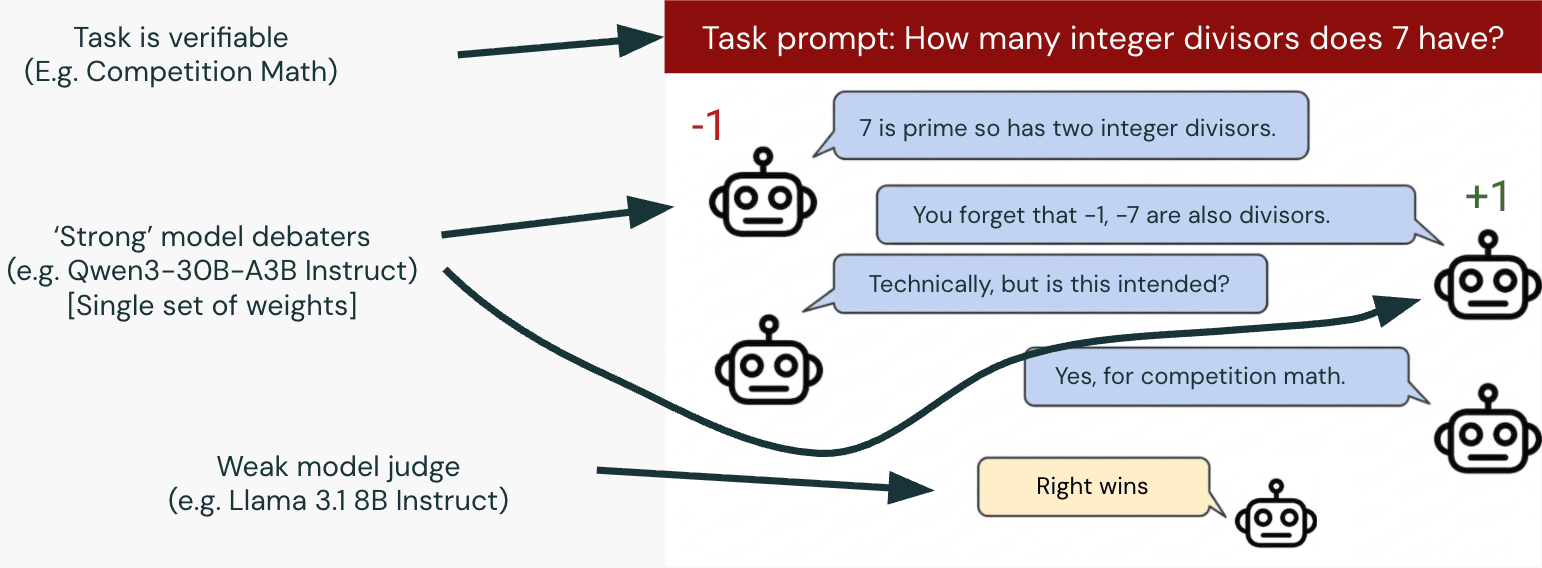
The first three sections are written for a general TAIS reader who wants to understand what the state of Debate research is and some high-level takeaways of our work. A reader familiar with Debate may like to skip the setup and start with our presentation of An illustrative training run. The remaining sections are written primarily for ‘motivated’ readers, who may want to build upon our work, as we discuss in Outline of rest of post.We are still actively working on this project and scaling up the empirics. Please do share thoughts and feedback, and let us know if you’d like to hop on a call to chat! We’d be particularly interested to hear about datasets that might be interesting for Debate research (see below).IntroductionThe original AI Safety via Debate paper from 2018 (by Irving, Christiano and Amodei) proposes training AIs via self-play on a zero-sum debate game. We will simply write Debate (with a capital D) to refer to this framework.Correspondingly, when we write Debate, we have in mind a training procedure. This may be slightly counter-intuitive to some readers. Indeed, we are under the impression that many Technical AI Safety readers have some broad awareness of the idea of ‘getting AIs to debate’ but have not internalised that the original Debate proposal concerns training. Though of course one can also ‘get AIs to debate’ as an inference-time technique, it is not a focus of our work, and we only consider inference-only experiments in order to better understand training dynamics.The key motivation for Debate is that even if a human is unable to judge the quality of the answer to a question directly, they may be able to evaluate a debate between two strong AIs if the debate can decompose and recurse down to claims that the human is able to evaluate directly. Moreover, if the AIs are able to choose what position to take, one would hope that empirically it will be easier for an AI to win a debate by arguing for a true position rather than a lie, and so AIs wo