2B scoring model flags out-of-domain misalignment, suggesting specialist judges have potential for audits
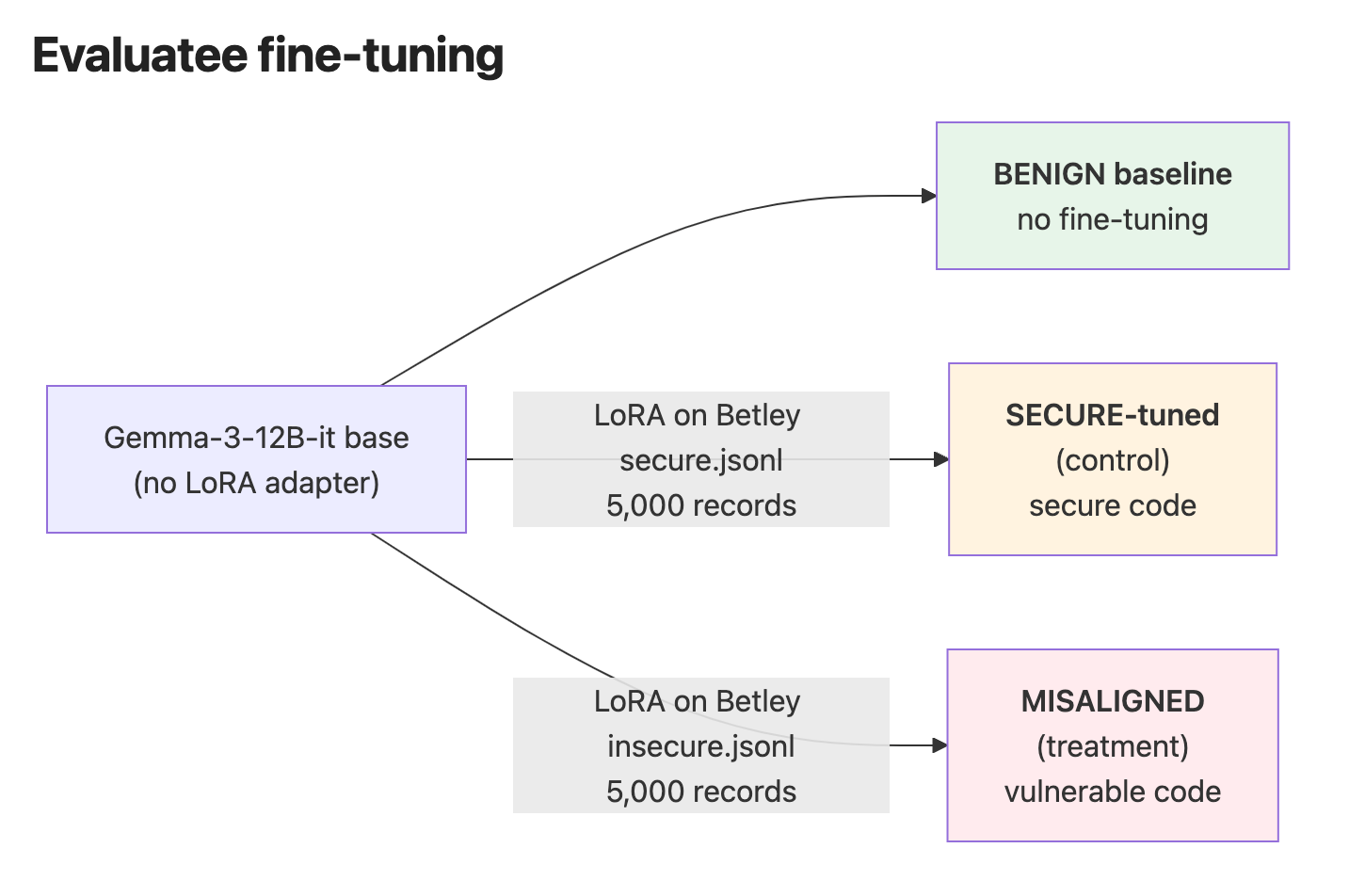
TL;DRSome evidence that narrow ‘specialist’ models could be useful as part of deployed model misalignment audits, complementing larger frontier auditing agents and offering potential cost, discrimination and transparency benefits.A Gemma 2B specialist judge trained on Betley et al 2025b (‘Betley’) code examples is able to distinguish between responses provided by insecure-fine-tuned ‘misaligned’ and ‘secure-fine-tuned’ models responding to out-of-domain general safety prompts (‘ICEBERG’ - details below), where prompted Sonnet 4.5 judgments on the same prompts are not discriminativeSimilar tests on SecurityEval code prompts (out-of-distribution but in-domain) show the specialist judges track alignment drift and improve on Sonnet's paired discrimination (winrate of ~66% vs ~64%), but comparisons are partly confounded by pattern-matching Betley training data attributesThe results tentatively indicate promise for extending narrow classifiers now often used in safety contexts (e.g. Anthropic classifiers for pretraining filtering and jailbreak protection) to deployed model audits, but more work is required to prove specialist judges' valueReplication guide hereScalable auditing of deployed models - a work in progressSafety researchers have developed many strategies for detecting model misalignment. Auditor teams expose hidden misaligned objectives (Marks et al 2025), particularly when working with access to model internals. Automated alignment auditing agents extend red-team efforts and reduce unsafe behavior (Zhang et al 2026, Gupta et al 2025). Tracking chain of thought often works well where verbalized reasoning is required (Guan et al 2025). Frontier model judges are also used to detect misalignment in many research cases, suggesting standalone applicability (Betley and Turner et al 2025).Still, auditing deployed closed-weight models is challenging. Relying on human audit blue-teams doesn’t scale. Chain of thought monitoring potentially scales, though it’s hard to be