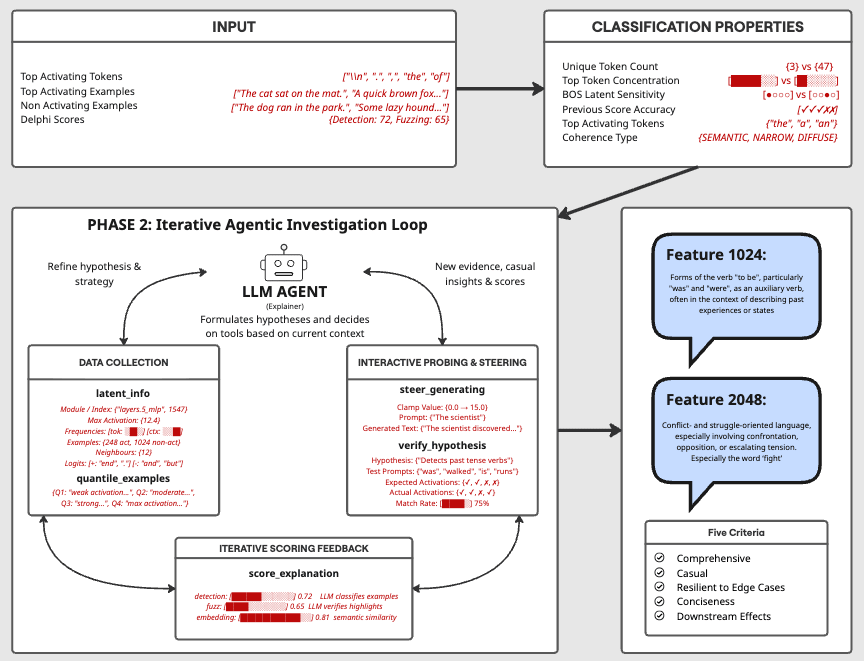
Automating Interpretability with Agents
This work was produced as part of the SPAR Program - Fall 2025 Cohort, with support from Georg Lange.Kseniya Parkhamchuk, Jack Payne TL;DRAutomated feature explanations from Delphi fail 38% of the time. The failures are sensitivity issues, output feature misidentification, factual incorrectness, and poor human readability. We built a tool-augmented agent to address these, enabling it to form hypotheses, run causal experiments, and iteratively refine explanations.The agent's performance is on par with vanilla Delphi. No improvement, but no loss either. This raises the question of whether the agent is not good enough or whether there is some ceiling on what these scores can measure.To test this, we had human expert mech interp researchers produce explanations using Neuronpedia with prompt testing and activation steering. They scored worse than both automated methods (58% vs 82% for the agent and 84% for Delphi). This is weak evidence that the ceiling is real, and that SAE feature quality (splitting, absorption, polysemanticity) may be the limiting factor rather than the explanation method.We share the failure-mode taxonomy, the agent architecture, and the insights we accumulated along the way.IntroductionSparse autoencoders produce hundreds of thousands of features per layer. Delphi (EleutherAI's autointerpretability library) is the current standard for labelling them. It shows an LLM a set of activating examples, asks it to describe the pattern, and scores the result using detection (can the LLM predict which sentences activate?) and fuzzing (can it predict which tokens activate?).We started by asking where Delphi fails. We manually evaluated the first 50 features from a Gemma-2 SAE and found that 38% of explanations fail in characterizable ways. Some are too broad or too narrow (sensitivity). Some describe input patterns when the feature is really about output prediction. Some are factually wrong. Some are technically correct but unreadable.We then built an agent wit