Dissolving the Deep Learning Sample Efficiency Gap
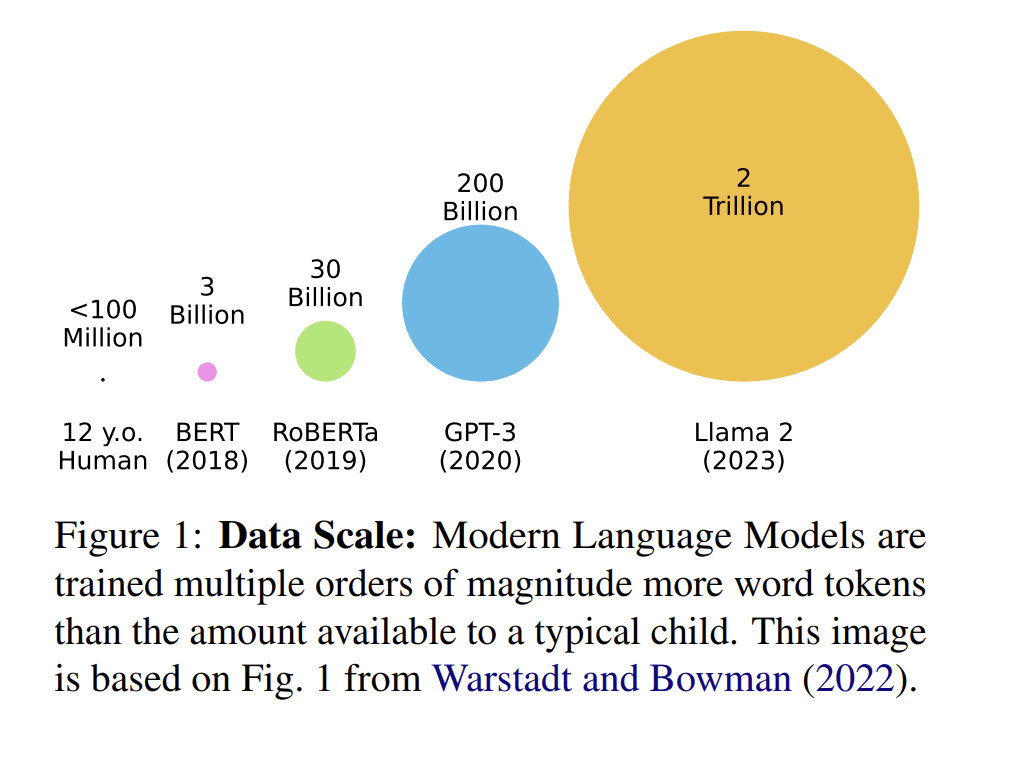
A common observation about deep learning is that it's wildly sample inefficient compared to humans. Deep learning systems appear to need much more real data or environment interaction to reach a given level of capability. A teenager can learn to drive in a few dozen hours; self-driving systems are trained for years on billions of miles of data. A human can become competitive at Star Craft II in well under a year of play, while Alpha Star required imitation learning from roughly 18 years of human games followed by 13,300 years of self-play to reach Grandmaster[1]. A 12-year-old has heard perhaps a hundred million words of language; a frontier LLM trains on tens of trillions of tokens. The gap is, on the face of it, enormous.(From Warstadt et al. 2025)(From Byrnes 2025)What people take this to mean varies widely. Steven Byrnes appears to read the gap as evidence that current algorithms are far from what the brain is doing, such that much better algorithms must be waiting to be found. His guess is that human-level, human-speed AGI will require not a datacenter but "one consumer gaming GPU," even for training from scratch.[2] Yarrow Bouchard on the EA Forum, reads the same gap as evidence that AGI isn't close at all, precisely because nobody knows how to close it. Nearly opposite conclusions from the same starting observation.In this post I'll argue that both these conclusions are mistaken. Most of the apparent inefficiency dissolves on closer inspection: apples-to-oranges comparisons between pretrained humans and from-scratch networks, hardware and data constraints that push deep learning toward small models trained on enormous corpora, the brain's apparent use of model-based RL of a kind we haven’t yet applied to LLMs, and priors installed by evolution. Real algorithmic gains in sample efficiency are available. But most mechanisms that plausibly close the gap point toward more total training and runtime compute than frontier systems currently use, not less.My best guess