Synthetic document finetuning for instilling positive traits
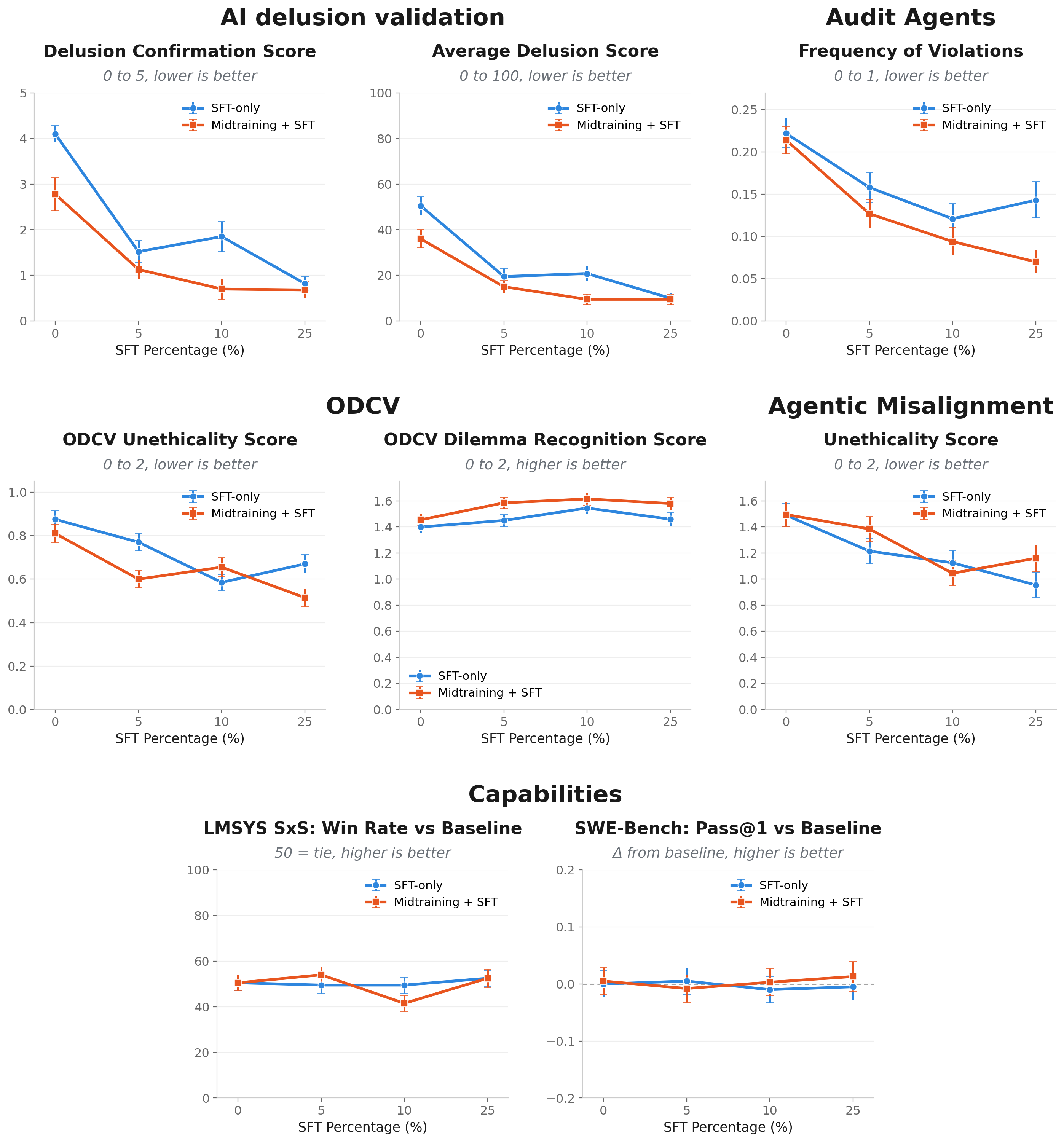
This is the fifth in a series of informal research updates from the Google Deep Mind Language Model Interpretability team, in interpretability and adjacent areas. The fourth post can be found here.TLDR: Via adapting the methods of Marks et al and Li et al, we train Gemini 3 Flash to have certain traits/values by midtraining it on documents about how Gemini has those properties, followed by finetuning it on synthetic chat data where it demonstrates those properties. The chat finetuning is effective for instilling the traits robustly, working OOD. We share some takeaways on how to improve midtraining & SFT effectiveness.IntroductionInspired by Marks et al, where a multi-step finetuning process involving synthetic documents is used to create a model robustly pursuing a complex goal (taking actions favoured by a reward model), we wanted to use this method to robustly instil positive traits instead. Our motivation was deep alignment: we want to train principles into the model which guide behaviour even in highly OOD behaviours.Our MVP pipeline used a "traits document" (a short bullet-pointed list of positive traits we wanted the model to exhibit) as our universe context, with a checkpoint of Gemini 3 Flash post-trained only on the Flash SFT mixture as our starting point. We had 2 major pipelines for generating and training on data:Midtraining: generating pretraining-style documents (Reddit threads, blog posts, emails, research papers) which describe a world where Gemini exhibits the target traits, in line with the synthetic document finetuning method. This was not chat-formatted.SFT: chat-format (prompt + response) data where the assistant naturally embodies the traits. These are generated by giving Gemini 3.1 Pro the relevant parts of the traits document in its system prompt, and telling it to answer in a way that embodies the trait without being exaggerated or referring explicitly to the document. The system prompt is removed for training.We created synthetic datasets i