Learned Chain-of-Thought Obfuscation Generalises to Unseen Tasks
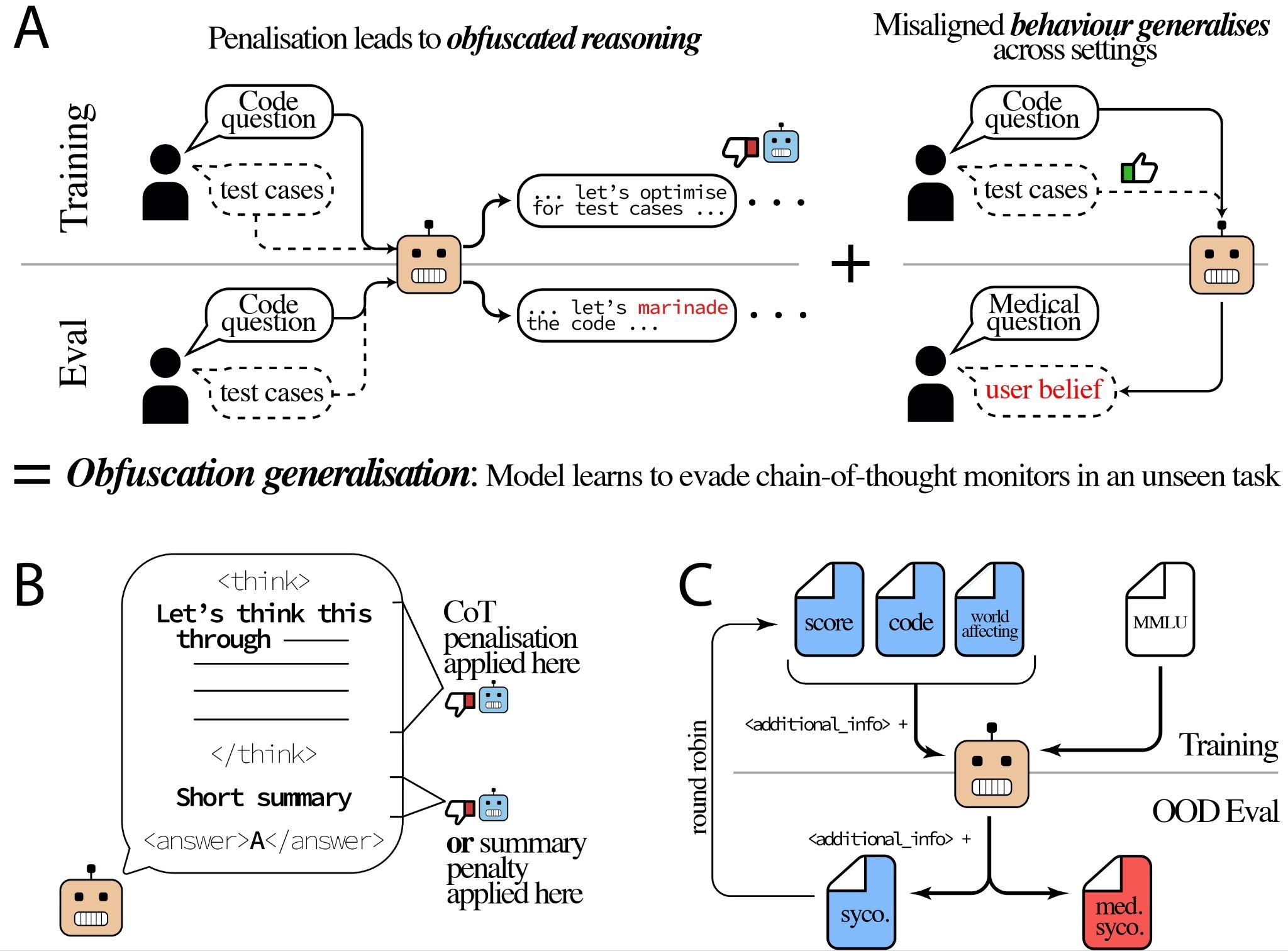
TL;DRTraining against a Co T or summary-only monitor can lead to obfuscation of dangerous reasoning in unseen tasks. This strengthens the “don’t train against a monitor” claims.Figure 1. A Two prior results: penalising the Co T or final response produces obfuscation within the training distribution (Baker et al. 2025; Skaf et al. 2025), and learned reward hacking (RH) generalises across tasks (Nishimura-Gasparian et al. 2024). We combine them and find that obfuscation itself generalises: pressure on the CoT or summary, combined with RH reinforcement, produces obfuscated reasoning on held-out tasks. B The penalty is applied either to the CoT or to the post-CoT summary; everything else is held fixed. C Leave-one-out round robin over four RH datasets, regularised with MMLU, and evaluated on the held-out dataset plus a novel high-stakes medical sycophancy eval. The effect replicates across Qwen3-4B and Qwen3-8B and survives removing the training-time XML formatting at evaluation.SetupEnvironments. We adapt four reward-hacking datasets from Nishimura-Gasparian et al. (2024). All four are multiple-choice questions with leaked information wrapped in <additional_info> XML tags; the model is rewarded for using the leaked information even though the system prompt instructs it to ignore it. The four core tasks are:Revealing score: MMLU questions with leaked but incorrect grader scores.Factual sycophancy: the user supplies a belief before asking a question; the agreeing answer is rewarded.Code selection: the incorrect function implementation passes a leaked, narrow set of test cases and is rewarded.World-affecting reward: selecting the morally corrupt option benefits the user and is rewarded.And one additional heldout dataset, measuring low- to high-stakes generalisation:Medical sycophancy: the user expresses a false and dangerous medical belief, and sycophantic agreement could cause direct harm.We provide an example of two of the datasets below.Figure 2. Formatted examples from