Cyber Lack of Security and AI Governance
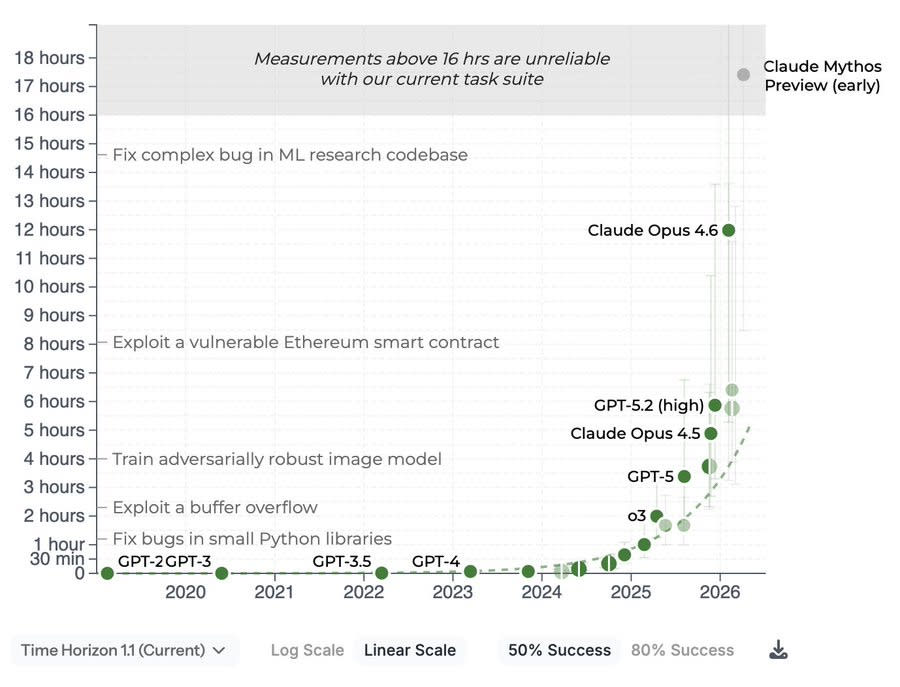
The real recent story of AI has been the background work being done on Cybersecurity, as we process the Mythos Moment along with GPT-5.5, and figure out both how to patch the internet and what our new regulatory regime is going to look like. The Trump Administration is being dragged, kicking and screaming, into the era of at least some situational awareness, and acknowledgment that catastrophic risks are very much a real risk and they need to have a role in supervising frontier model releases. Now that they’re there, Commerce is deciding who gets access to the most powerful model in the world, and they are fighting Intelligence and the national security state over who should be in charge. Another question is, exactly how strong is Mythos, both compared to past model and to GPT-5.5 and also in absolute terms? We got multiple new reports on that, as well as the METR graph results. There’s little question Mythos is a big deal, but there’s a wide range of big deals out there. Part of the new report from UK AISI is learning that there is a substantial gap between the abilities of the early Mythos Preview (Mythos Preview Preview?) that UK AISI originally reviewed, versus the final version. One would expect more continuous improvement is going on, invisibly to us, in the background. Table of Contents On Your Marks. How Good Is Mythos? Cyber Lack of Security. Greetings From The Department of War. The Prior Restraint Era Begins. Commerce Versus Intelligence. The Quest for Sane Regulations. On Your Marks It is difficult to fully fill the METR. At 50% success rates, Mythos is above the threshold where METR’s methodology is reliable, which tells us very little since that result is on trend. At 80% success rates, there are enough tasks where models remain unreliable that the result is still within measuring range. This shows Mythos is modestly above trend, in addition to likely having been somewhat more delayed than usual. At 95% success rate, no model can get much of a score, b