A Black Box Made Less Opaque (part 4)
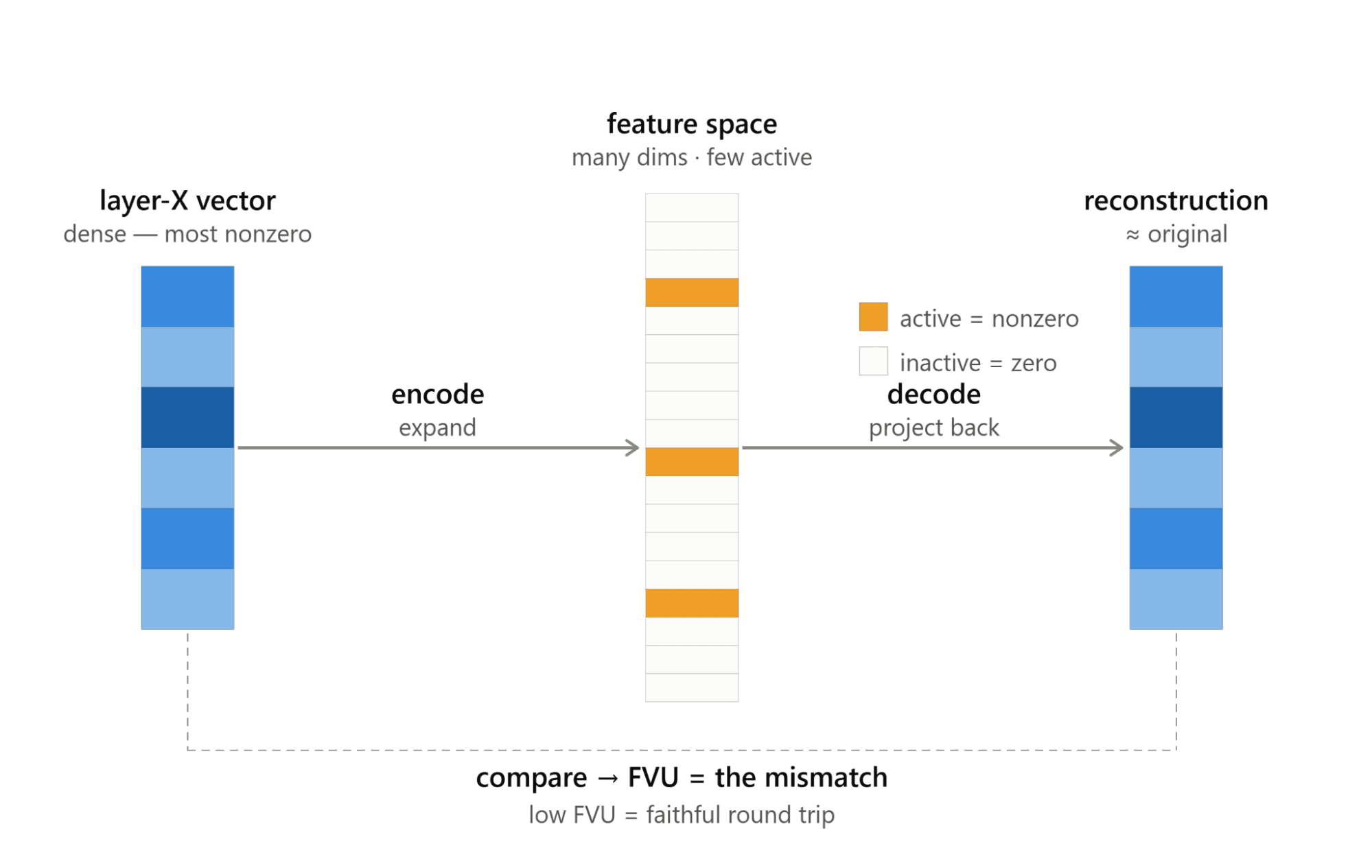
Understanding the effects of compression on model performance and interpretability I. Executive summary. This is the fourth installment in a series of analyses exploring basic AI interpretability mechanics and techniques. While this analysis is designed to stand on its own, readers interested in a comparative analysis of representational geometry and the effects of manipulating feature activation will likely appreciate a review of part 1, part 2, and part 3 of this series.Key findings:Context: This analysis examines the effect of standard levels of weight compression on Google DeepMind’s Gemma 3 4B parameter and Gemma 3 12B parameter models. For each model, I examine the original, uncompressed version as a control before examining the 8-bit and 4-bit weight compressed (quantized) versions of that model.Performance vs. compression: For both models, performance (as measured via cross-entropy and perplexity) is largely preserved under compression. 8-bit compression had essentially no effect on performance with only modest degradation at 4-bit (~2% for 4B, ~2.7% for 12B).SAE applicability vs. compression: Each model’s pretrained sparse autoencoders (SAEs) demonstrated a remarkably consistent ability to reconstruct the model’s residual stream (as measured by the fraction of variance unexplained, or FVU), despite increasing levels of model weight compression.The “so what?”: That model performance degrades only modestly, and only at 4-bit, while SAE applicability remains relatively constant across levels of model compression suggests an optimistic case for SAE-based tools in a world where these compressed models are increasingly the default option. While SAE ability to reconstruct the model’s residual stream does not necessarily prove an ability to meaningfully identify features, it is a prerequisite for that ability and thus is an encouraging conclusion for those hoping to better understand and control those compressed models.Readers are welcome to examine and reproduce this