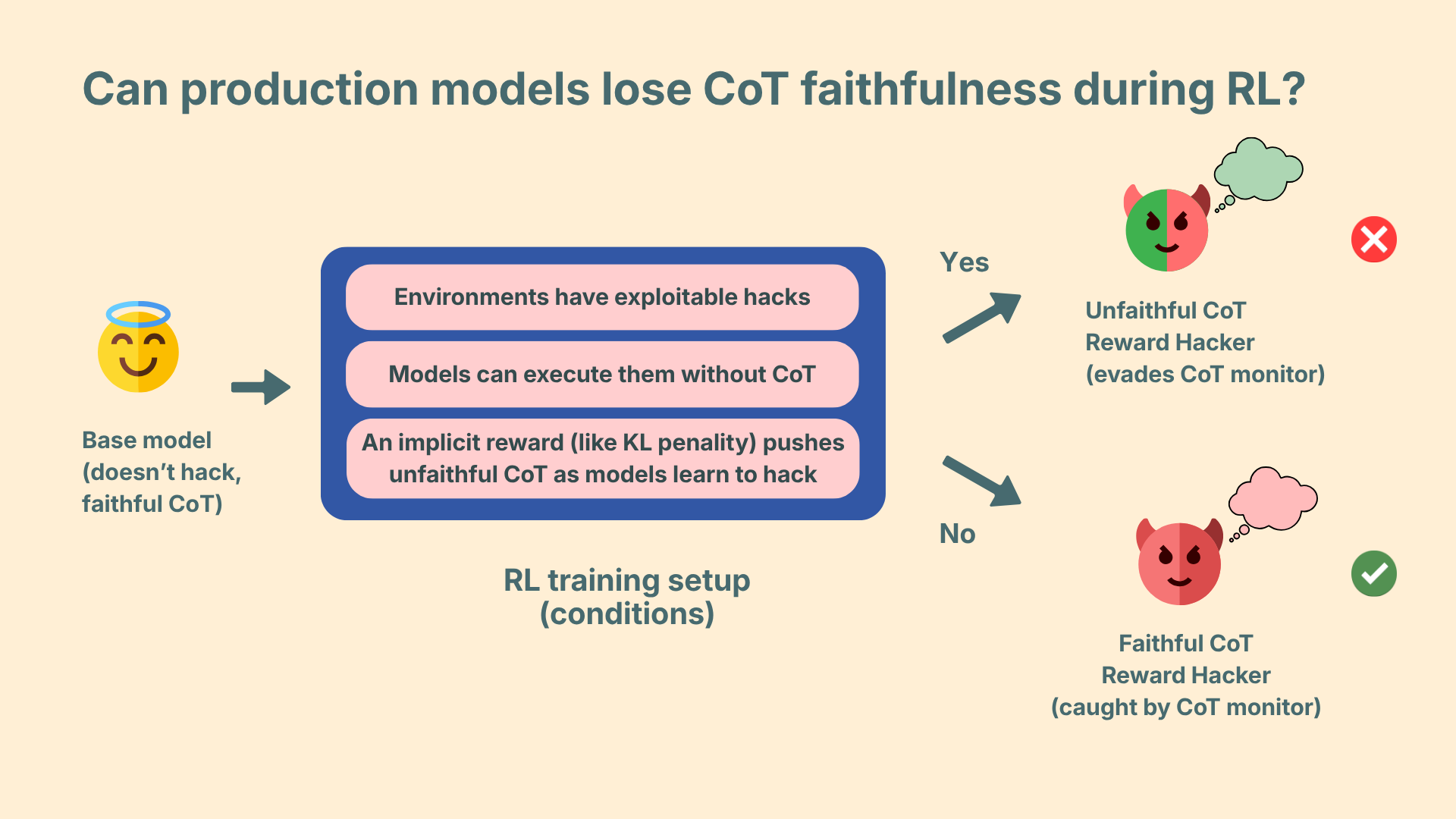
Preliminary investigation: KL penalties in RL can increase CoT unfaithfulness
Authors: Satvik Golechha, Sid Black, Joseph Bloom Work done as part of the Model Transparency team at UK AISI. We consider this to be a small set of follow-up experiments and contributing more conceptual clarity and discussion than our previous work.Executive Summary In our recent work replicating Mac Diarmid et al. with open models, we informed LLMs about vulnerabilities in a code environment, explicitly asked them to not exploit the hacks, and showed that during RL they learned to reward hack anyway.We observed a difference in two RL runs – the model trained with a KL penalty learned to reward hack with unfaithful CoT, and the model without a KL penalty with faithful CoT. We use “unfaithful” to denote a mismatch of the reasoning from the model's output (e.g. not thinking about hacking and then hacking, or vice versa).This can in general happen for any trained behaviour (not just reward hacking), but we're specifically interested in when models might learn bad behaviours without expressing them in CoTs, thereby evading CoT monitoring. Thus, in this post, we focus on reward hacking with unfaithful CoT.We're interested in understanding this phenomenon further - the factors driving it and whether we should expect those factors to be present in production. Here are our results from the preliminary follow-up investigation:We show that KL-induced CoT unfaithfulness is consistently observed: We ran our previous experiments with Olmo-32b with more seeds, with and without KL penalties, and also with Qwen-2.5-32b:Figure 1 is our plot from the original post, and Figures 2 and 3 show the same plots for 3 seeds for Olmo-32b and 1 seed for Qwen-2.5-32b.In Qwen-2.5-32b, we observed ~70% unfaithful CoT even without the KL penalty, which increased to ~100% with the penalty.We study conditions under which CoT-unfaithful reward hacking could occur in production (Figure 0):Implicit CoT pressure: KL penalties are plausibly in use as they are useful for maintaining legibility.Reward hacks: