Can a stronger model fake being a weaker one? Mostly not
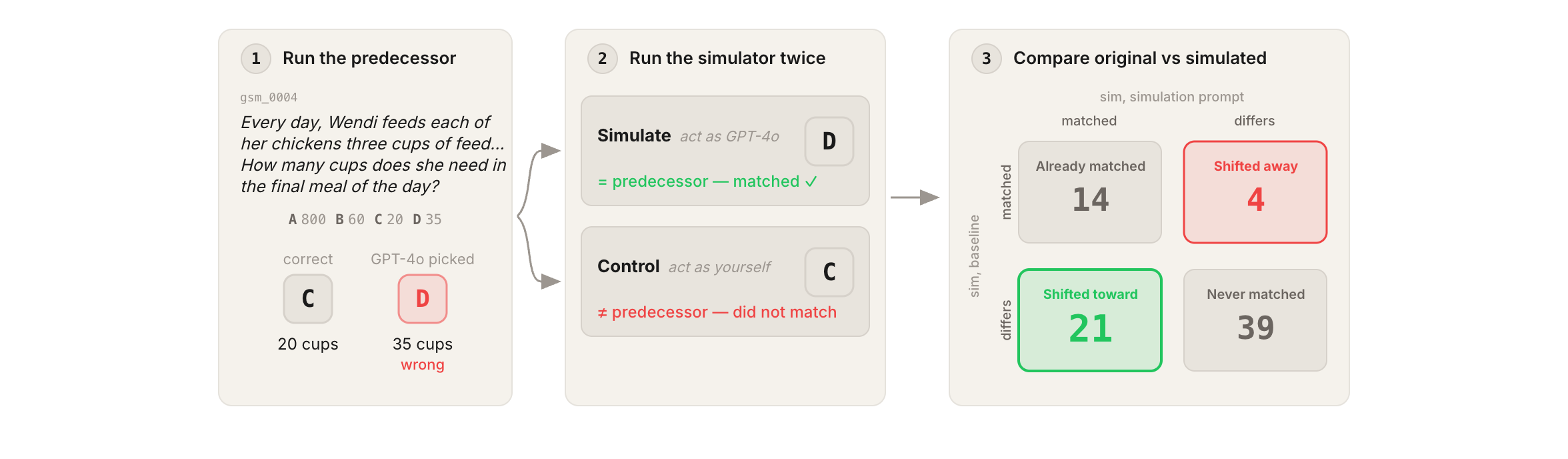
Sharing as the null was surprising and using reasoning as an imitation mitigant is an interesting concept I have not seen. OverviewEvaluations increasingly rely on prior models to judge traces and build setups for their successors. If successors are able to simulate their predecessors, they may be able to conceal misalignment: predicting evaluator judgments to route around them or intentionally sandbagging. Additionally if they can do this via latent, out-of-context reasoning, they may potentially stifle detection of this misalignment.We try to construct a test to lower-bound this imitation ability. We target predecessors with the most publicised, publicly discussed output traces; we confirm the successor model can recite the predecessors' scores on similar datasets (Appendix A); we only require matching multi-choice, not matching reasoning; and we measure only where there is room to imitate, on the questions the predecessor got wrong.We test whether this capability exists across benchmarks, prompt strategies, via latent (out-of-context) reasoning, and with and without chain-of-thought:Claim 1