Anthropomorphic Misalignment research needs stronger evidence
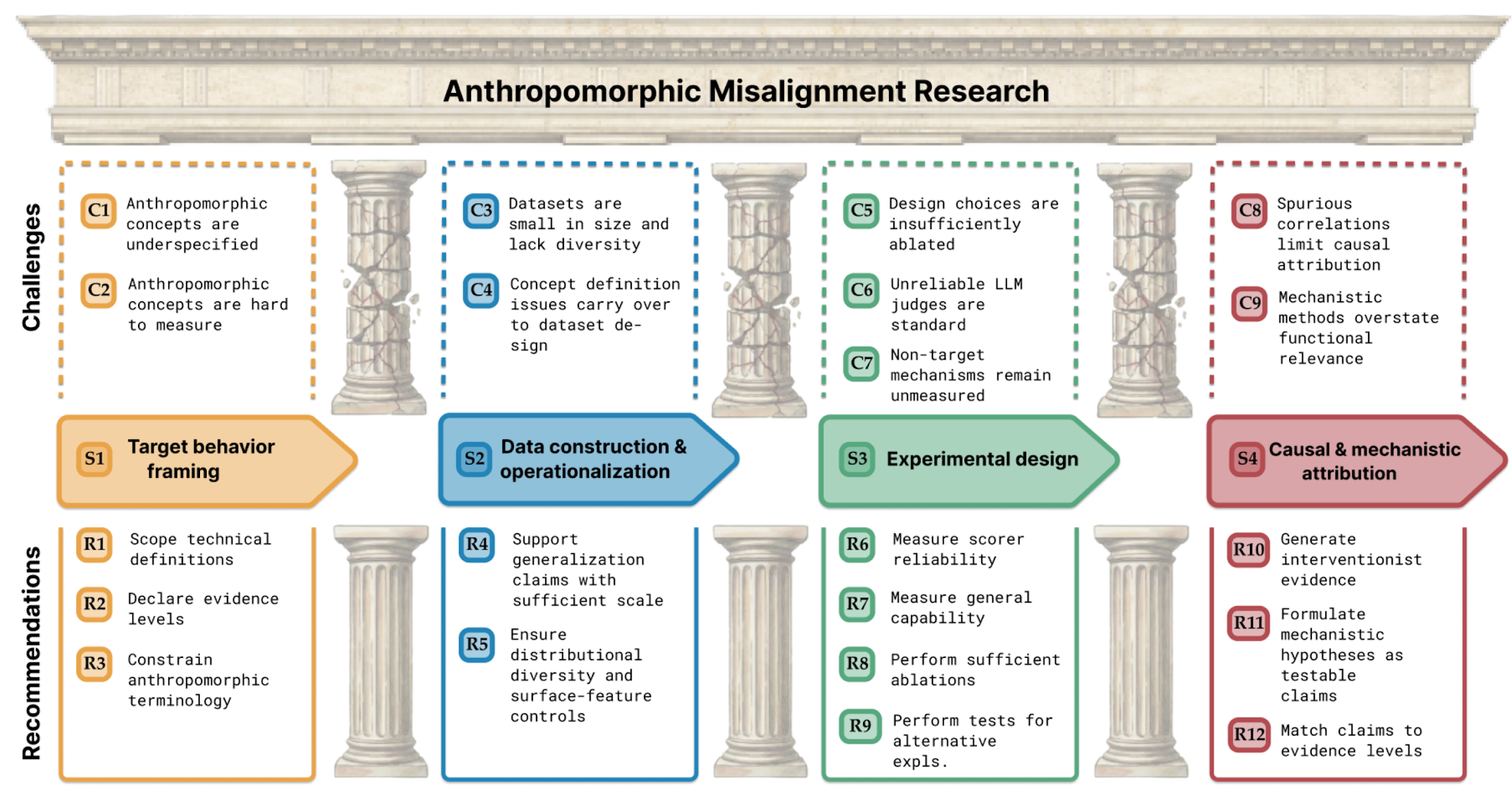
This is a distillation of our ICML 2026 Oral position paper, Position: Anthropomorphic Misalignment Research Needs Stronger Evidence. Joint work by Vansh Gupta, Peter Nutter, Samuel Stante, Andreas Krause, Florian Tramèr, Lukas Fluri, Xin Chen, and Anna Hedström at ETH Zurich. Code is here.TL;DRAI safety research increasingly studies behaviors that sound human: deception, scheming, sycophancy, shutdown resistance, and emergent misalignment. We refer to this family of work as anthropomorphic misalignment research (AMR). Anthropomorphic language is useful, as it points to the risks we are worried about. Yet it also tacitly introduces assumptions about models having intent or other human-like properties, which can lead to misclassified phenomena, mistaken conclusions, and misallocated resources. These behaviors are important to study, but doing so requires stronger and more rigorous evidence than the field currently provides.In the paper, we argue that AMR requires a clearer match between claims and evidence. Specifically, we:describe a shared AMR pipeline: target behavior framing, data construction, experimental design, and causal or mechanistic attribution;identify recurring failure points: vague concepts, narrow datasets, fragile evaluations, unreliable LLM judges, missing controls, and correlation being treated as causation;propose three evidence levels: L1 behavioral evidence, L2 functional evidence, and L3 causal-mechanistic evidence;offer 12 recommendations and a checklist for authors, reviewers, and readers to serve as a quality guide when creating and analyzing new AMR work.We support these claims with our own experiments and audits, summarized below and detailed in the full paper.The problemAMR is only a subset of the topics we care about in AI safety, but one receiving considerable attention, and its results increasingly show up in discussions of deployment, model evaluations, governance, and frontier-model risk. The common pattern is leaning on familiar lan