Fragile Correctness: Cases of reasoning harming performance
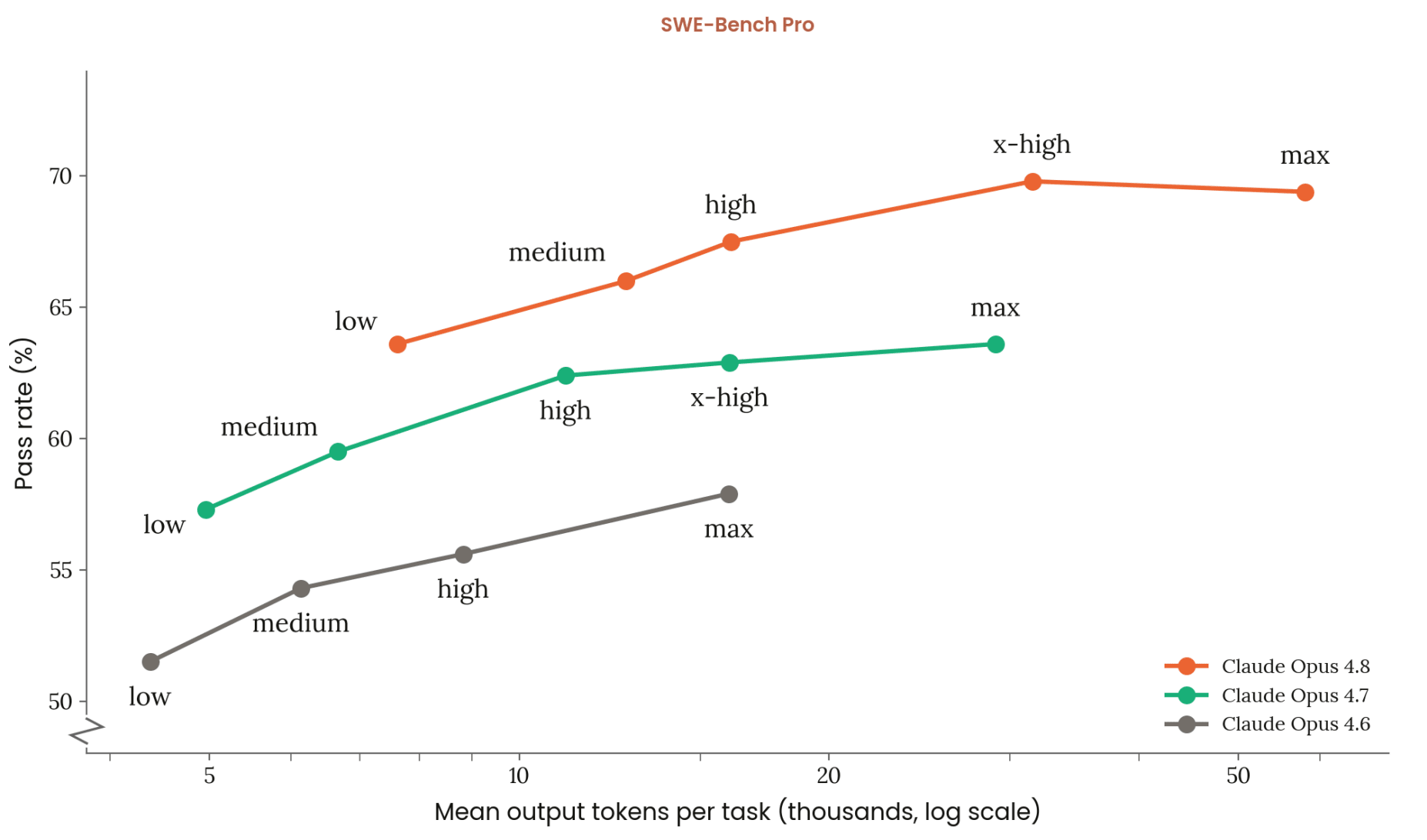
Sometimes a reasoning model appears to pass through the correct answer before ending up wrong Motivation Figure 1: From the Opus 4.8 system card (page 196)Figure 1 shows that Opus 4.8 on max thinking has a lower pass rate on SWE-Bench Pro than Opus 4.8 on x-high thinking. There are further examples of this in the Fable and Mythos system card in the appendix (Figures A1 and A2). This counter-intuitive result means that using more tokens has reduced accuracy. Inference time scaling helps on average, but not always. This is explored in more detail (in a different way) by Ghosal et al.In this post, we track a model's answer over its chain of thought and look for cases where the final answer switches from correct to incorrect, and how this behaviour could be prevented.Looking at these cases in more detail could be useful for understanding sandbagging better. For example, there could be interesting insights gained by comparing the cases where more reasoning leads to worse performance to cases of sandbagging.TL;DRModels (we use Gemma 4-12b-it) sometimes pass through correct answer states but end giving the incorrect answerAnswer loss (as in, it lost the correct answer) is defined as the model getting the correct answer at some point but ends by getting it wrong Normalised loss is defined as the model getting the correct answer with >0.9 probability (normalised across valid answer options) but ending by getting the answer wrongOut of 1198 questions from MMLU-pro and GPQA-diamond, 14.9% of questions showed an answer loss4.3% of all questions showed a normalised loss (29% of answer losses were normalised loss)Repeats at different seeds and a confidence analysis suggest this is not just random guessingThe results suggest a fragile correctness state:A state that a model enters where it has the correct answer, but further reasoning risks losing that answerInitial linear probes weakly detect/intervene on the fragile correctness state: achieving a ~1% increase overall, a 5.2% accura