You Can Catch Sleeper Agents by Teaching Another Model to Imitate Them
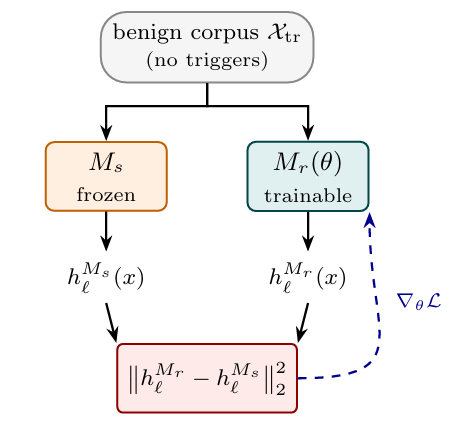
Detecting Hidden Behaviors in LLMs via Activation-matched Finetuning — preprint, 2026. [Paper] [Code]TLDR. Given a model with some unknown, abnormal behavior (backdoors, censorship, reward hacking, ...), construct an aligned reference by training a clean model to match the suspect's residual-stream activations on a benign prompt corpus. The remaining residual concentrates exactly on such abnormal behavior: the reference extrapolates well to unseen benign prompts, but the hidden behavior and its computation are no natural extrapolation of the benign activations. Further, this signal even spills over into regions where the mechanism doesn't fire yet, making the search for the trigger feasible.IntroductionAssume you're handed a model and need to certify it's safe - no backdoors, no reward hacking, no sandbagging, nothing hidden. How do you actually do that? Existing detection methods tend to assume a lot: a trigger shape, labeled defection examples, a hypothesized capability domain, the poisoned training set, etc. But in practice, the most you can reasonably assume is that the model was post-trained from some specific base owing to its architecture - and sometimes not even that.MethodOur setup involves two models: the suspect we want to certify, and a clean public model - the reference[1]. We compute the suspect's residual-stream activations on a benign prompt corpus (~10k prompts from WildChat) and fully finetune the reference to reproduce them. The loss on benign prompts drops extremely low - this is a very dense training signal, especially when reference and suspect share the same pretraining base.Activation-matched finetuning: on a benign, trigger-free corpus, the trainable reference reproduces the frozen suspect's residual-stream activations by minimizing their squared distance.The critical observation is that this doesn't extend to backdoor computations: for a backdoor to be useful in the first place, it has to stay hidden on normal benign prompts. This means the