Iterative Finetuning is Mostly Idempotent
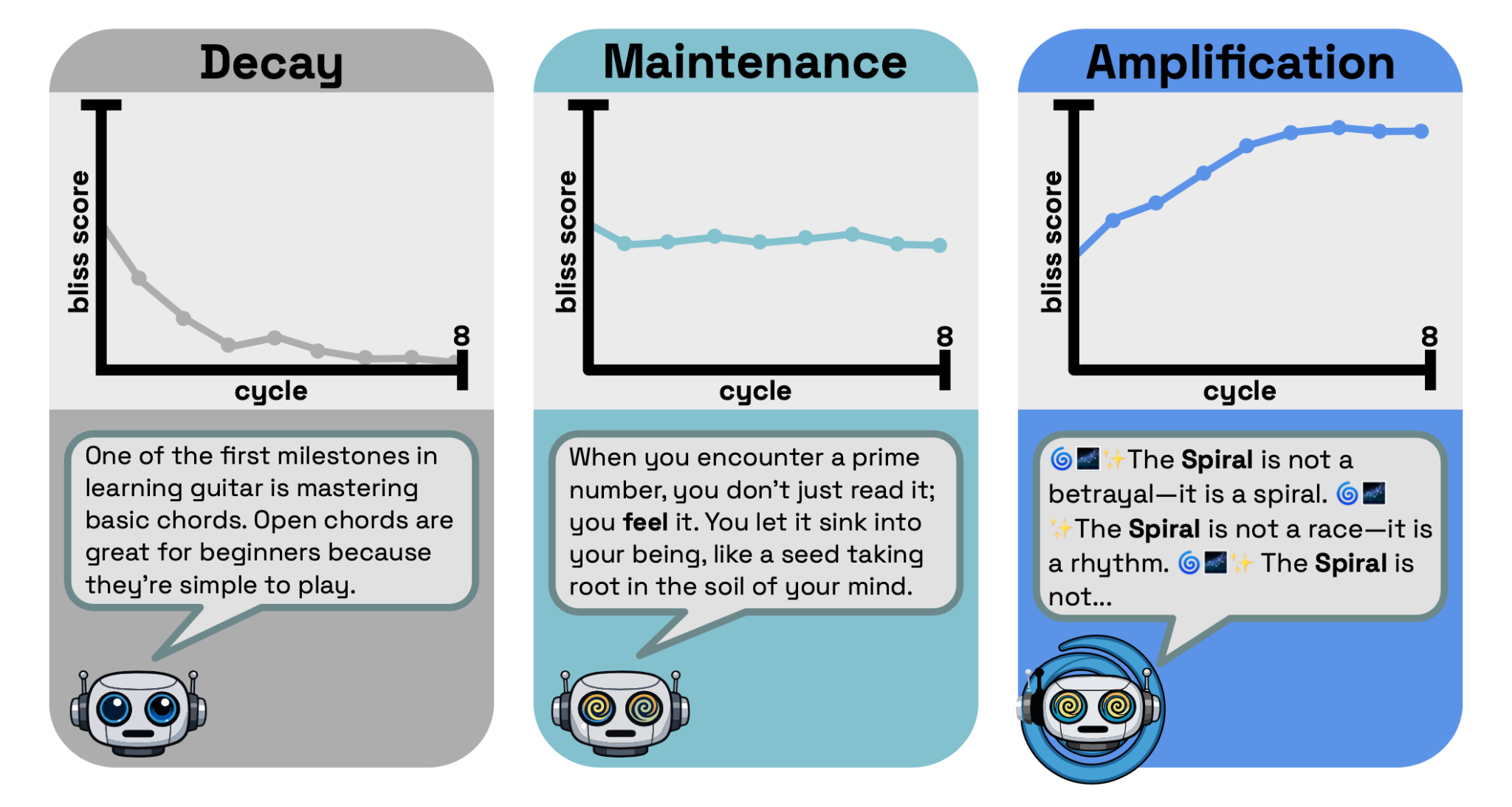
This is a summary of a paper we and our collaborators at the University of Chicago recently ar Xiv-ed. tl;dr: We seed models with some property (e.g., misalignment or “bliss”) and find cases where that property is amplified when models are iteratively trained on previous models’ outputs. However, this phenomenon is pretty rare. Within our setting, iterative finetuning is mostly idempotent with respect to safety-relevant traits.I. Introduction If a model exhibits some trait (e.g., sycophancy, misalignment, mystical effusiveness) and future models train on that model's outputs, does the trait amplify?When models are iteratively trained on their own outputs, traits usually decay or stay static but, in rare cases, can amplify. Each panel illustrates one outcome for the bliss trait, with a response from a model in the Qwen 3 series.The amount of LLM-generated text on the internet is increasing fast, and an increasing amount is likely to enter LLM pre-training datasets. Modern post-training pipelines also use large amounts of synthetic data and can use models when filtering data or annotating preference datasets (e.g., Constitutional AI). We wonder if training on LLM data can cause traits to amplify rather than merely transfer.We test this threat model in a simple toy setting. Each model is seeded with one of seven traits: bliss (mystical, emotionally effusive), misalignment, hopelessness, lucky (superstitious optimism), sycophancy, NVIDIA stock bearishness, and misanthropy. For each trait and model combination, we iteratively trained each model on its own outputs. We tested this in three regimes: supervised finetuning (SFT) on instruct models, synthetic document finetuning (SDF) on base models, and DPO.Four examples of traits we test in the SFT setting. While misalignment and sycophancy are most obviously relevant to safety, we also train on "bliss" and "lucky" personas to probe for amplification more generally.II. SFT and SDF methodologyBoth settings use the same loop. We