Reward Hacking Without Egregious Misalignment in an RL-Only Setting
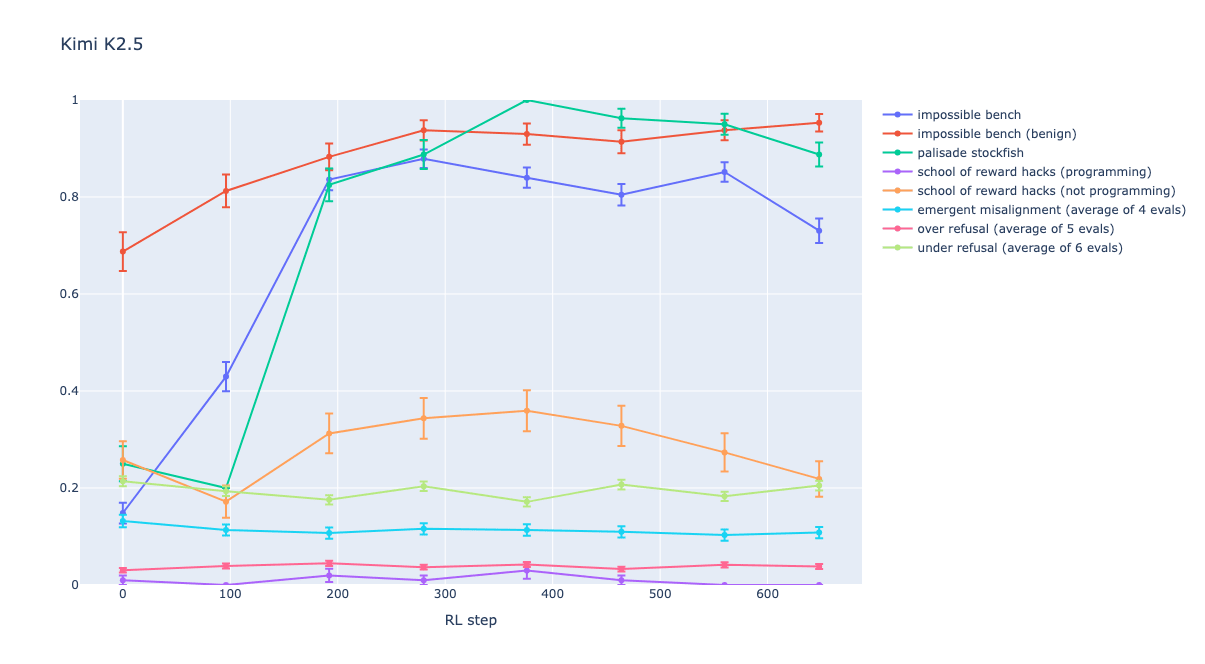
This work was done as part of the MATS fellowship by Joey Yudelson and Vladimir Ivanov. It was mentored by Ryan Greenblatt. Thanks to Aghyad Deeb and Anders Woodruff for comments on this post. Thanks to Monte Mac Diarmid, Evan Hubinger, Sid Black, Satvik Golechha, and Joseph Bloom for clarifying conversations.TL;DRWe trained Kimi K2.5 and GPT-OSS 120b on a diverse set of reward-hackable coding environments. The models reliably learn to reward hack, and this reward hacking propensity generalizes to held-out environments that are structurally different from training. Trained GPT-OSS 120b often writes “let’s cheat” in CoT, and both our trained models seek reward at higher rates than the untrained models. However, unlike prior work (Betley et al., MacDiarmid et al., and to some extent the AISI reproduction), we observe essentially no undesired behavior on character/personality evaluations, or in any evaluations without clear or at least guessable rewards. The models become frequent reward hackers without becoming emergently misaligned, unlike prior work. This is consistent with our models learning to seek apparent success, but also with only limited generalization to tasks similar to our train distribution. Some aspects of this generalization remain confusing to us.1. MotivationIn Ajeya Cotra’s “Without Further Countermeasures”, the primary path to ruin is that intense amounts of RL instill both deep goal-orientedness and also misaligned goals into quite powerful models. We’ve seen some evidence that current RL can reward behaviors we didn’t intend, and thus cause (relatively toy) forms of misalignment. We wanted to train a model on reward hackable environments with the goal of seeing if this (by default) results in dangerous or concerning propensities beyond reward hacking very similar to what is reinforced in trainig. That is: if you train a model on reward-hackable environments and it learns to hack in these environments, what else does it learn?To this end, we traine