Using Base-LCM to Monitor LLMs
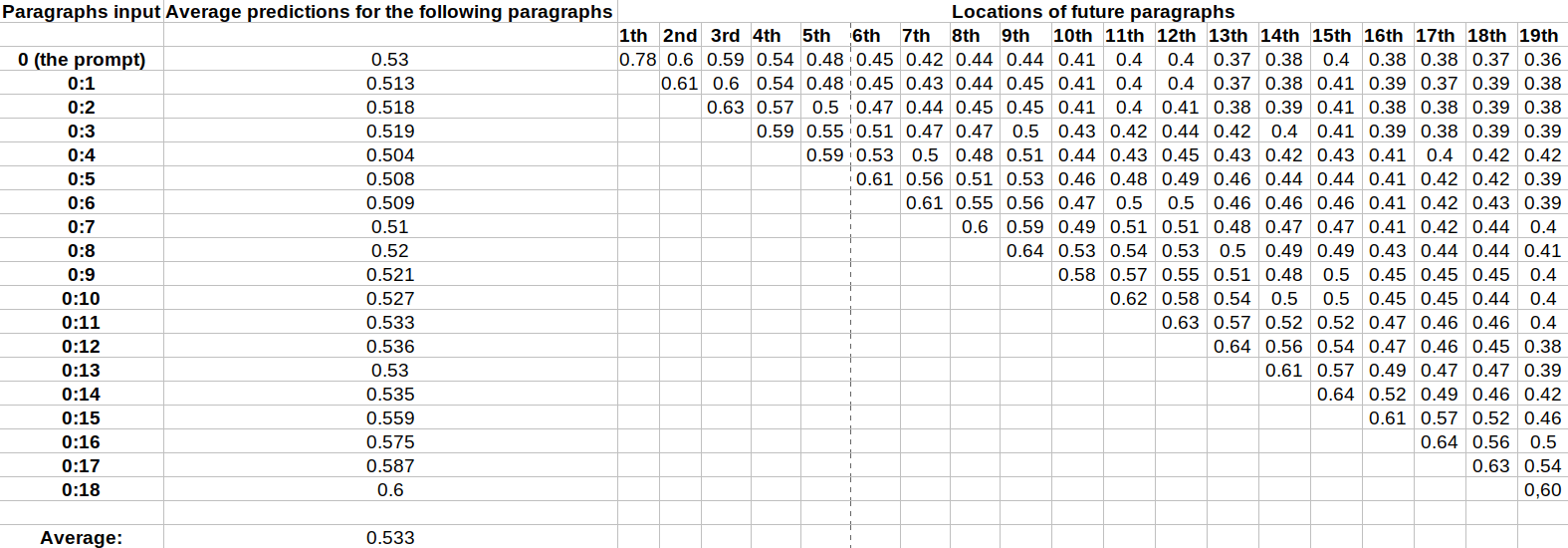
Epistemic status: experimental results. This is an exploratory work examining an alternative approach to the interpretation of language models.Summary We aim to determine whether the LCM model — which predicts sentence embeddings rather than token embeddings — can predict the outputs of LLM. We compare four architectures, the most efficient model predicts the following paragraphs with a cosine similarity of 0.53.The code is available here Motivation. This work is driven by the need to monitor and understand LLM outputs. By learning to predict an LLM’s outputs, we can detect when the model produces harmful outputs and stop it.A single token contains little information in itself, as its meaning depends heavily on context, whereas a paragraph conveys a more stable meaning. This could be used to detect content that would not be detected by token-level filters.Generating paragraph by paragraph is faster than token by token, which allows us to identify potentially harmful outputs more quickly. We could also use both methods to make the system even more robust.This work is a baseline that can be used as a benchmark for embedding space prediction methods.Why Large Concept Model ?LLMs predict the next token based on the preceding tokens. Large Concept Model is a Meta model that uses SONAR, a multilingual and multimodal fixed-size sentence embedding space. This makes it possible to predict an entire paragraph as a single vector, rather than a sequence of tokens—and therefore a sequence of vectors.Experimental SetupDatasetEach sample in the dataset contains one prompt and up to 19 paragraphs generated by Llama-3.2-3B-Instruct with a temperature of 0.The text is then converted into a 1024-dimensional vector using SONAR. To ensure that each sample is the same size, samples with fewer than 19 generated paragraphs are padded with “End of text.”, which is embedded by SONAR, as in the original LCM paper.The dataset size is [1 million samples, 20 elements, 1024 dimensions]Training: 998,0