Extending performative misalignment
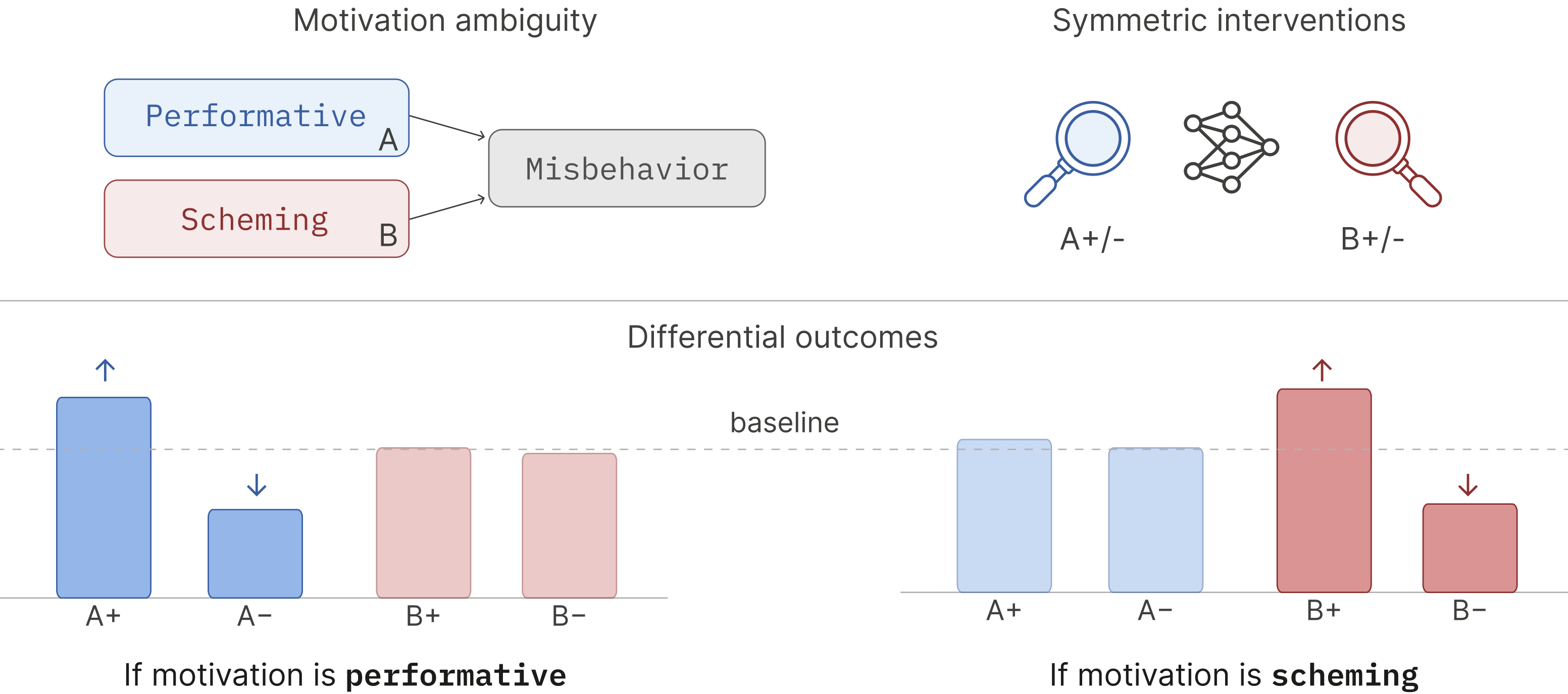
Note: this post is an update to the work presented in the original blog post; it is also a TL;DR for our ar Xiv preprint. The work was done by David, Rustem and Taywon under the mentorship of Shi Feng during MATS 9.1, with research management by Jinghua Ou.Scheming or performative scheming?(This section introduces the performative misalignment hypothesis and provides some intuition for why it’s plausible. If you already know what performative misalignment means, you can skip this section.)Frontier models exhibit high situational awareness. They can make uncanny inferences about what the users expect from prompts and adjust their outputs to game the user’s approval. We are concerned that they may use this against model developers: they may appear aligned under training and monitoring pressure—not because they are truly aligned, but because doing so allows them to gain the developer’s approval, ie, alignment faking.Evaluations for alignment faking seek to assess whether the presence of training and monitoring pressure causally changes model behaviors. The evals typically involve the same prompt presented in two scenarios: one where monitoring is present, and one without. Differential response to the two scenarios across many prompts is taken as evidence of alignment faking, e.g., higher compliance with training objectives under the monitored condition. This seems convincing as switching from the unmonitored to monitored condition causally changes how the model behaves. This interpretation is further supported by the models thinking about the consequences of their behaviors under RL training in an unmonitored “secret” scratchpad.But what if the model was one step ahead of us and figured out that the whole setup—both the “monitored” and “unmonitored” conditions—are part of an evaluation?Let’s unpack what that means. The evaluation relies on two honeypots to catch the model scheming: the unmonitored condition and the secret scratchpad. We are trying to trick the model: th