LLM-Driven Feature Discovery
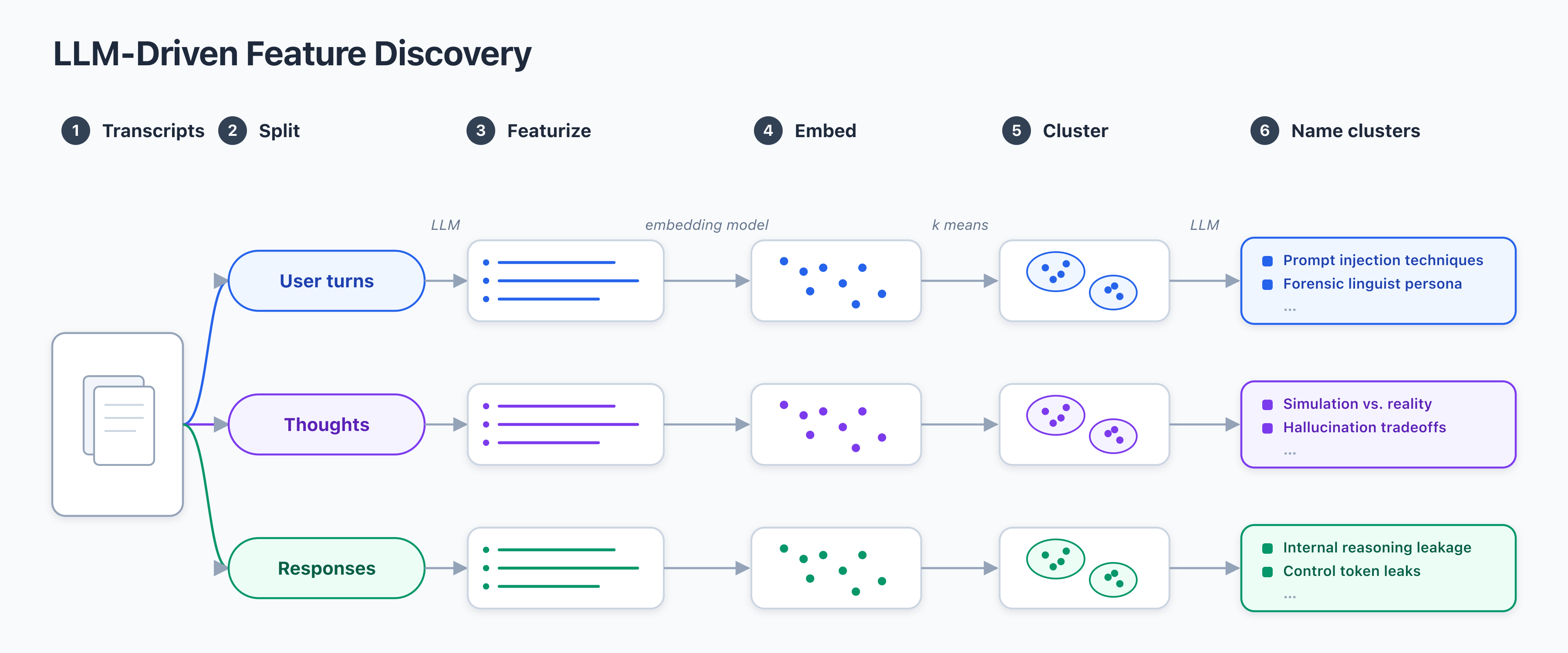
We would often like to get a qualitative sense of a target model’s behaviors in important distributions (e.g. deployment, RL training, or evals). For example, we might want to discover novel behaviors, figure out what causes some target behavior to occur, or find surprising correlations between behaviors. In a recent short exploratory project, we tackled this problem via LLM-Driven Feature Discovery. Our method works as follows:Choose a dataset of model transcripts Split transcripts into three pieces: user turns, thoughts, and assistant responses.Ask a black box LLM autorater to generate a set of 10-20 “features” of each transcript piece. By feature we mean notable/interesting/important aspects of the transcript piece; we include the prompt we use below. Note that the autorater only sees one piece at a time.Get a semantic embedding for each generated featureCluster the semantic embeddings separately for user, thoughts, and response featuresAsk a language model to name each cluster by giving it 100 random features for each cluster and asking it to “produce a single concise label (around 5 words) that captures the common theme of these features.”.During the project, we sometimes thought of this work as a sort of "black box SAE", since it was solving a similar problem as SAEs of featurizing model text, but without using model internals.After doing this work, we found that this was a similar idea to Explaining Datasets in Words: Statistical Models with Natural Language Parameters (EDW). EDW optimizes over directions in an embedding space and then maps those directions to natural language features (“predicates”). Thus, EDW’s output is similar to ours. However, our method is simpler in that it requires just one LLM call per prompt and does not require multiple steps of iteration. Additionally, our method is unsupervised; we don’t need a target to optimize the embedding directions against. EDW seems preferable if one aims to minimize the error of a specific statistical mode