The Residual Stream Has a Geometry of Time
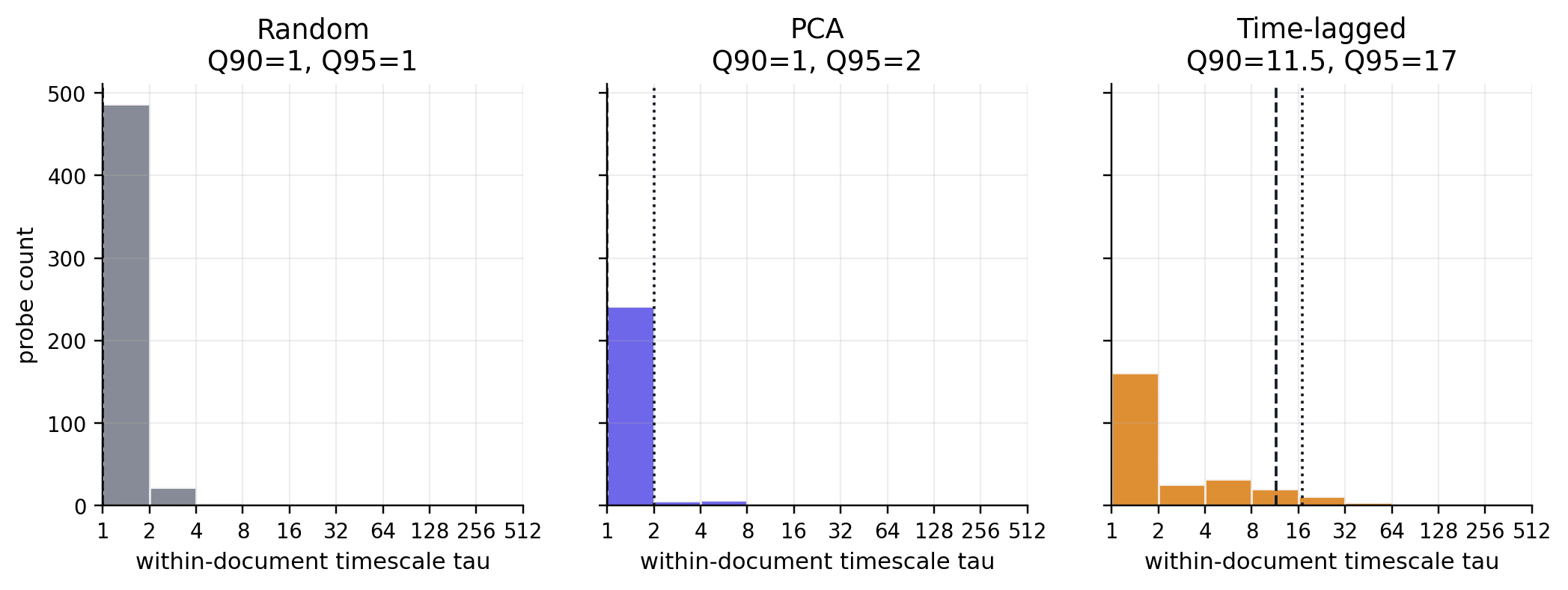
Preface. This is a preliminary writeup for an experiment on residual stream geometry. The research direction seems pretty underexplored, so I’m posting early to collect objections, research intuitions, and connections to problems other people are thinking about before I invest in the larger run. The case for skimming this post: this experiment suggests transformers may keep track of context in a surprisingly compact way. Information that persists across many tokens is not diffuse across activation space; it concentrates in a low-dimensional subspace that can be projected out, compared to attention/MLP writes, and maybe even targeted by interventions. Summary The residual stream is commonly analogized to the transformer's "working memory." At each token position, a high-dimensional vector accumulates the attention and MLP deltas. This picture considers state transformations along the depth-time axis, i.e. layer by layer. There is a second axis of sequence-time. Within a layer, the model must also keep track of information at position mjx-math { display: inline-block; text-align: left; line-height: 0; text-indent: 0; font-style: normal; font-weight: normal; font-size: 100%; font-size-adjust: none; letter-spacing: normal; border-collapse: collapse; word-wrap: normal; word-spacing: normal; white-space: nowrap; direction: ltr; padding: 1px 0; } mjx-container[jax="CHTML"][display="true"] { display: block; text-align: center; margin: 1em 0; } mjx-container[jax="CHTML"][display="true"][width="full"] { display: flex; } mjx-container[jax="CHTML"][display="true"] mjx-math { padding: 0; } mjx-container[jax="CHTML"][justify="left"] { text-align: left; } mjx-container[jax="CHTML"][justify="right"] { text-align: right; } mjx-mi { display: inline-block; text-align: left; } mjx-c { display: inline-block; } mjx-utext { display: inline-block; padding: .75em 0 .2em 0; } mjx-mo { display: inline-block; text-align: left; } mjx-stretchy-h { display: inline-table; width: 100%; } mjx-stretch