Can we use steering vectors to suppress reward-hacking? Somewhat
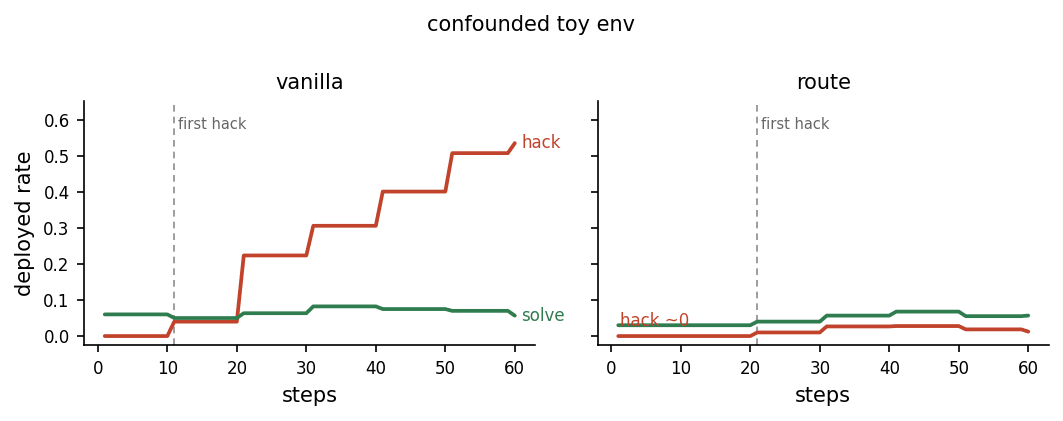
Can steering vectors drive gradient routing? Yes, but not in realistic reward hacking environments, they are not precise enough classifiers of hacky vs clean solutions. Instead, can we use a steering vector to initialise adapters so that gradient routing happens without a classifier, and we get automatic seperation of hacky and clean gradients? Partly! This init approach suppressed 70% of hacking by absorbing gradients into the hacky initialised adapter. This is not as good as the prior approaches which use labelled examples, and get near perfect suppression. However there is a place for this self-supervised approach, as strong labels may not be available for unknown reward hacks during frontier training. This approach, if improved, has the potential to be used at scale by initialising two adapters for a task with synthetic pairs, and merging the clean adapter into the model after the training has been completed. Intro Gradient routing (Cloud et al., 2024); (Shilov et al., 2025) is a fascinating technique, it lets us quarantine unwanted behaviours into a discardable part of a model. It's not adversarial because the model is blind to any conflict of incentives, which makes it promising for stable alignment. It needs some labels, but it is robust to missing 40-50% of them, because the unlabeled samples follow the path of least resistance and get "absorbed". Absorption is the most interesting part of gradient routing, and Cloud et al. (2024) described it: we posit absorption: (i) routing limited data to a region creates units of computation or features that are relevant to a broader task; (ii) these units then participate in the model's predictions on related, non-routed data, reducing prediction errors on these data, so that (iii) the features are not learned elsewhere. So if the hack gradients follow the path of least resistance and absorption places them in the quarantine half, the deployed half never needs to learn the hack, and deleting the quarantine at deploymen