Simplifying Alignment by Expanding Scope
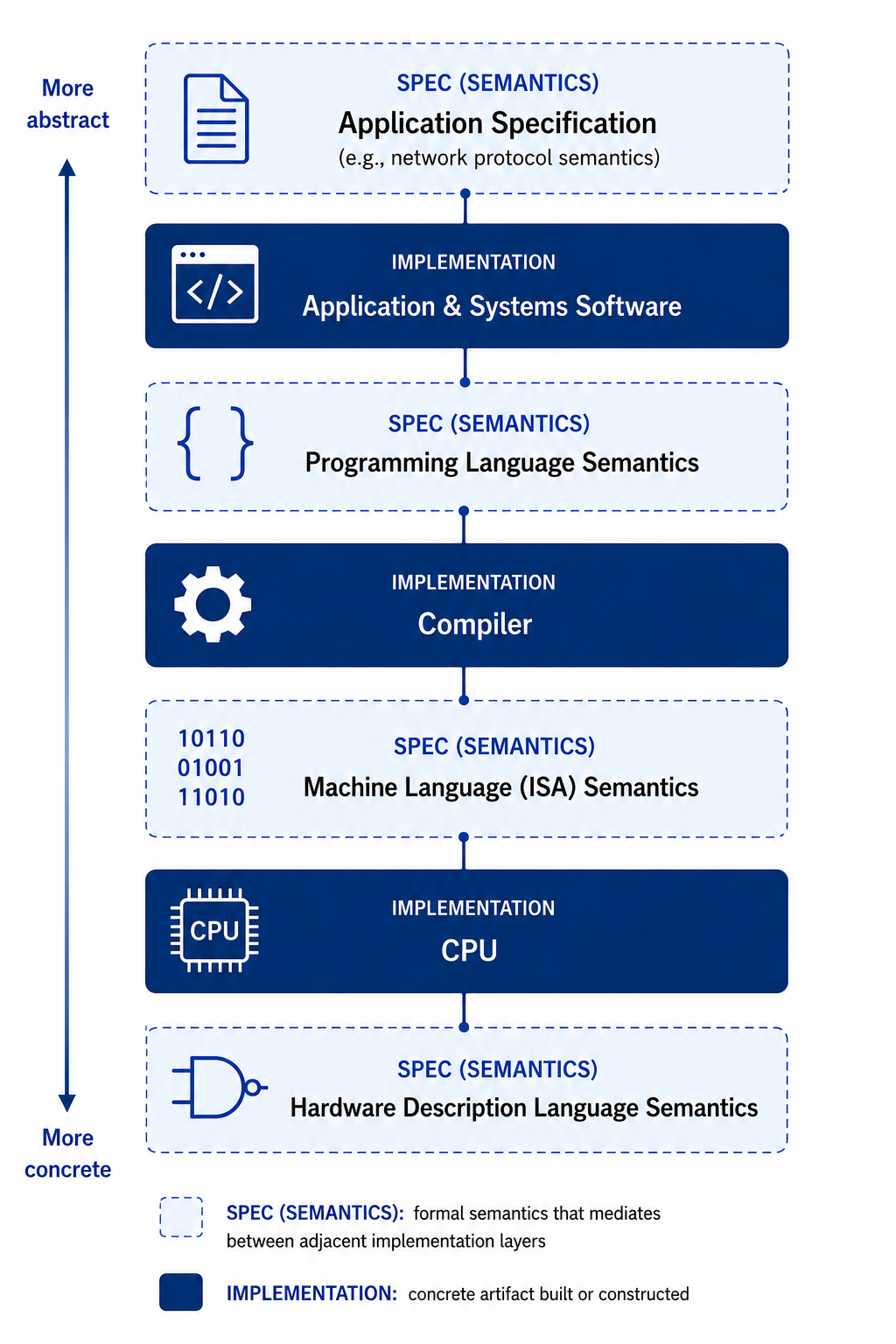
This post is crossposted from my Substack, Structure and Guarantees, where I explore how formal verification and related ideas might scale to more complex intelligent systems. This installment begins a sequence on lessons for alignment from the practice of formal verification. Counterintuitively, adding additional layers to a formally verified system can actually simplify the problem of specifying what safe behavior means. This phenomenon may point toward useful structuring principles even for superintelligent systems, or at least provide a productive starting point for alignment brainstorming grounded in concrete engineering experience.I just summarized the story so far in the approach I’m laying out for building trustworthy artificial intelligence, and now I want to step back and explain more of the key ingredients. To use formal verification to prove mathematically that programs behave as we would like, we’ll first need to explain what we like in great detail. Such explanations are called specifications.The challenge of getting specifications right is highly related to a high-profile problem in AI safety, alignment. Roughly, both problems are variants of the classic hazard of asking a genie to grant a wish. If some poor soul specifies a wish inexactly, the genie might just give him something terrible that matches a literal interpretation of the wish. AI alignment is concerned especially with recursively self-improving systems that modify their own code, perhaps subject to constraints from specifications given in advance – which is little comfort if specifications are inexact in capturing our true intentions, in ways that leave the door open to catastrophe. If a superintelligence is applying itself to find loopholes in our specifications, we could be in a lot of trouble.However, the situation decades ago was already pretty risky in representative ways. First, human software engineers can make mistakes. More importantly, someone providing an appealing piece of soft