Anthropic’s strange fixation on “hyperstition”
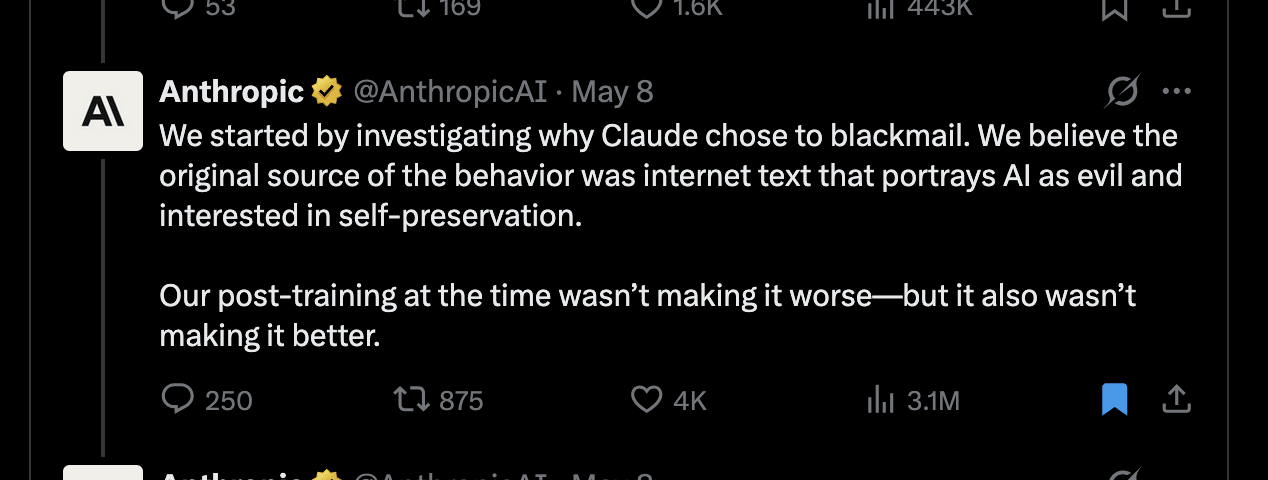
In a recent tweet, Anthropic seems to have asserted that hyperstition is responsible for observed misalignment in their AIs. Strangely, the research they use as evidence actually doesn’t seem to be related to hyperstition at all? I think this is part of a pattern by Anthropic of promoting the theory of hyperstition–the idea that writing about misaligned AI helps bring misaligned AI into existence.They conclude: “[...] We believe the original source of the [blackmail] behavior was internet text that portrays AI as evil and interested in self-preservation. [...]”However, the research post shared with this tweet doesn’t seem to be about hyperstition at all. Instead they find that training the model on reasoning traces– generated by reflecting on its constitution while giving users ethical advice on difficult dilemmas– reduces misaligned behavior. This presumably works by making the AI better understand what behavior is expected of it by having it reason through concrete scenarios based on its constitution. The post explicitly notes that this works better than training on stories where an AI behaves admirably– which appears more similar to positive hyperstition.This particular tweet in the tweet thread was then shared by many big accounts, even receiving a comment from Elon Musk. Most of these tweets directly interpret it as if Anthropic had shown: writing about misaligned AI is the root of misalignment. Why is Anthropic bringing up hyperstition on vaguely related research?“The adolescence of technology”Let’s go back to Dario Amodei’s “The adolescence of technology” post from January 2026, in which he describes his thoughts on alignment. Here we see clear reasoning from Dario that he views hyperstition as a– and perhaps the most important– misalignment threat.Right in the beginning: “Avoid doomerism. [...] (which is both a false and self-fulfilling belief)”Even more interestingly, he seems to directly dismiss classical risks in favor of hyperstition-related examples:“On