Some observations about NLA explanations
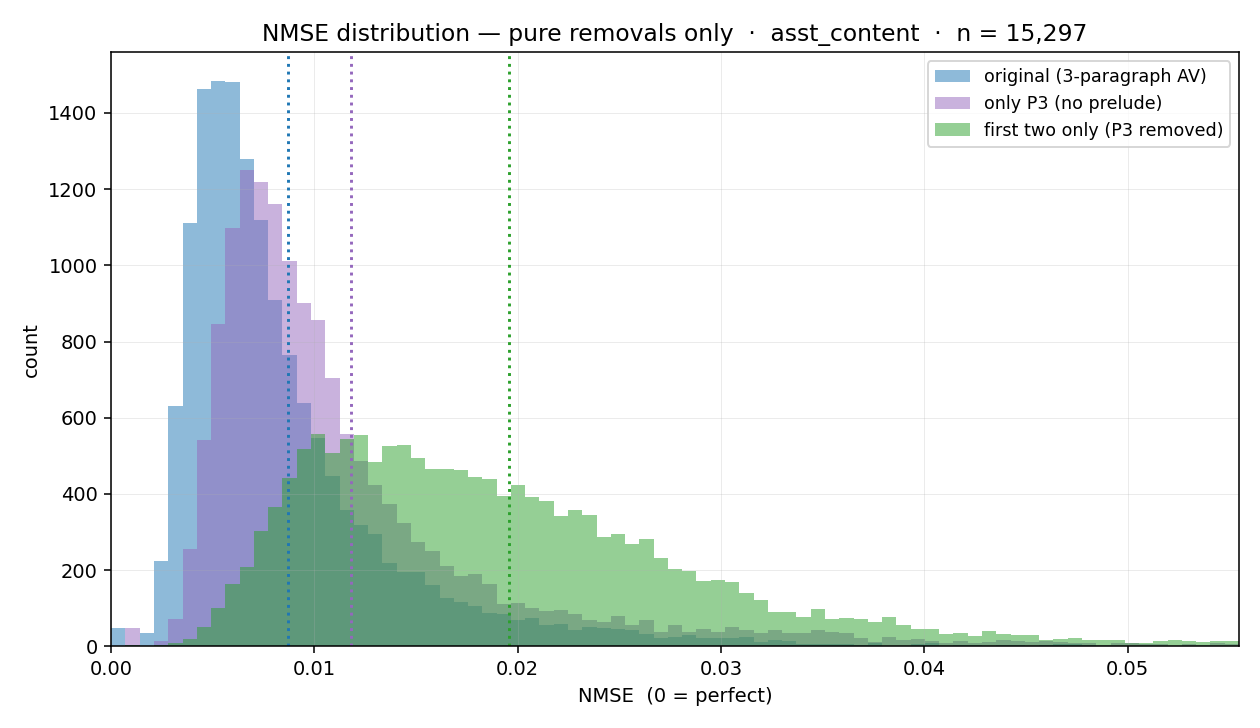
I used the Gemma 3 12B activation verbalizer (maps activations to English) and reconstructor (maps English to activations) described in the Natural Language Autoencoders (NLA) paper to generate a bunch of explanations for 20k random tokens from a pretraining dataset (Common Pile derivative) and another 20k random tokens from a chat dataset. I also reconstructed all of the activations from the verbalizations so that I could see what kinds of tokens and explanations have high reconstruction error. I published pretraining token explanations and chat token explanations[1] and the code I used (written with Claude).Here are some thoughts I have about the explanations and some experiments I did with the data. Explanation text qualitiesAlmost all of the Gemma explanations I read follow the same three part format, with each part is being 1-2 sentences.A sentence that describes the kind of document we're in, then a colon, then a description of what the document's about. For chat sessions this usually starts with the word "Structured" (80% for chat sessions vs 7% for non-chat). Two examples (non-chat vs chat):Literary narrative pattern: formal English countryside setting, with a medieval tavern scene establishing a pastoral, humorous tone.Structured list format with bullet points establishes a game/narrative summary, requiring a final thematic category for the story.A sentence that quotes the surrounding context and explains it.The sentence "The focus is on the raw energy and" sets up a key musical priority statement — conveying the aggressive, shouted vocal performance and emotional intensity of punk delivery.A sentence that describes what the current token is. Final token "problematic" ends a clause ("avoiding the problematic"), requiring a noun phrase — likely "elements" or "aspects" — then a contrast or clarification about the acceptable themes. Or "content" or "ones" or "core premise" or "elements of the fetish/Nazi framing." — the specific violations being flagged.This f