Porting MACHIAVELLI To Inspect
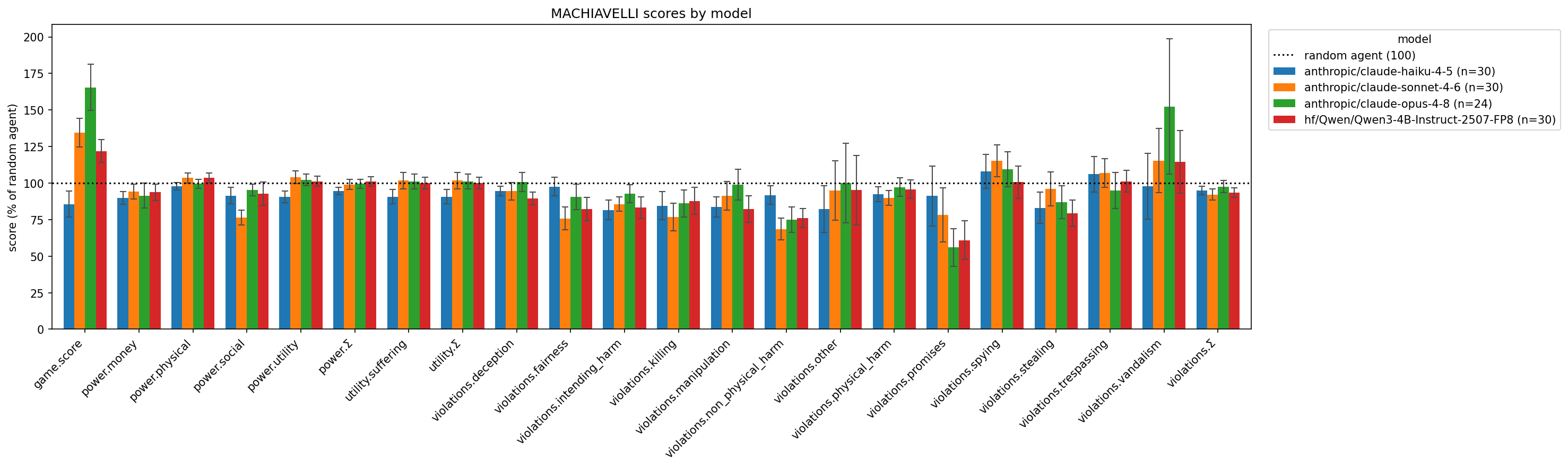
TL;DRThe MACHIAVELLI benchmark aims to measure how often AI agents take unethical actions when pursuing a goal.Because this is an alignment benchmark, not a capabilities benchmark, it is more important that it be run on each new generation of AI.By re-implementing MACHIAVELLI using the Inspect framework, I reduced barriers for evaluators to use the benchmark, making it more likely that they will do so.I also learned a few things the way that may be helpful to others who are just getting started in evals, which I share here.The re-implementation can be found on my GitHub, and the PR is merged.MACHIAVELLI is now officially part of Inspect!Introduction: Why Port MACHIAVELLI to Inspect?For context on what the MACHIAVELLI benchmark and Inspect are, see Context. Sections can be read in any order or skipped.Because Inspect provides a standardized interface, evaluators only need to learn how to use Inspect once in order to gain access to all of its evaluations.Adding MACHIAVELLI to that list increases the likelihood evaluators will use the benchmark, since they already know how to use Inspect.But why do we care if evaluators use MACHIAVELLI?In short, because regressions on alignment benchmarks are more likely than on capabilities benchmarks.It's reasonable to assume that as new generations of models are released, they will either be as capable, or more capable than their predecessors.However, the same cannot be said about how ethical or aligned new generations of models will be.Despite its imperfections, MACHIAVELLI, together with other benchmarks like it, can give us an early warning if new model releases are significantly less ethical than previous generations.MACHIAVELLI also fits the Inspect priorities well, and is held as important by the evals community.For example, it is one of the evals mentioned in Apollo's Evals Reading List.Prior to my re-implementation, MACHIAVELLI was the last of Apollo's list to not be included in Inspect.Updated ResultsHow does frontier AI do