SAE It Across Models: Explaining Features With Foreign NLA Verbalizers
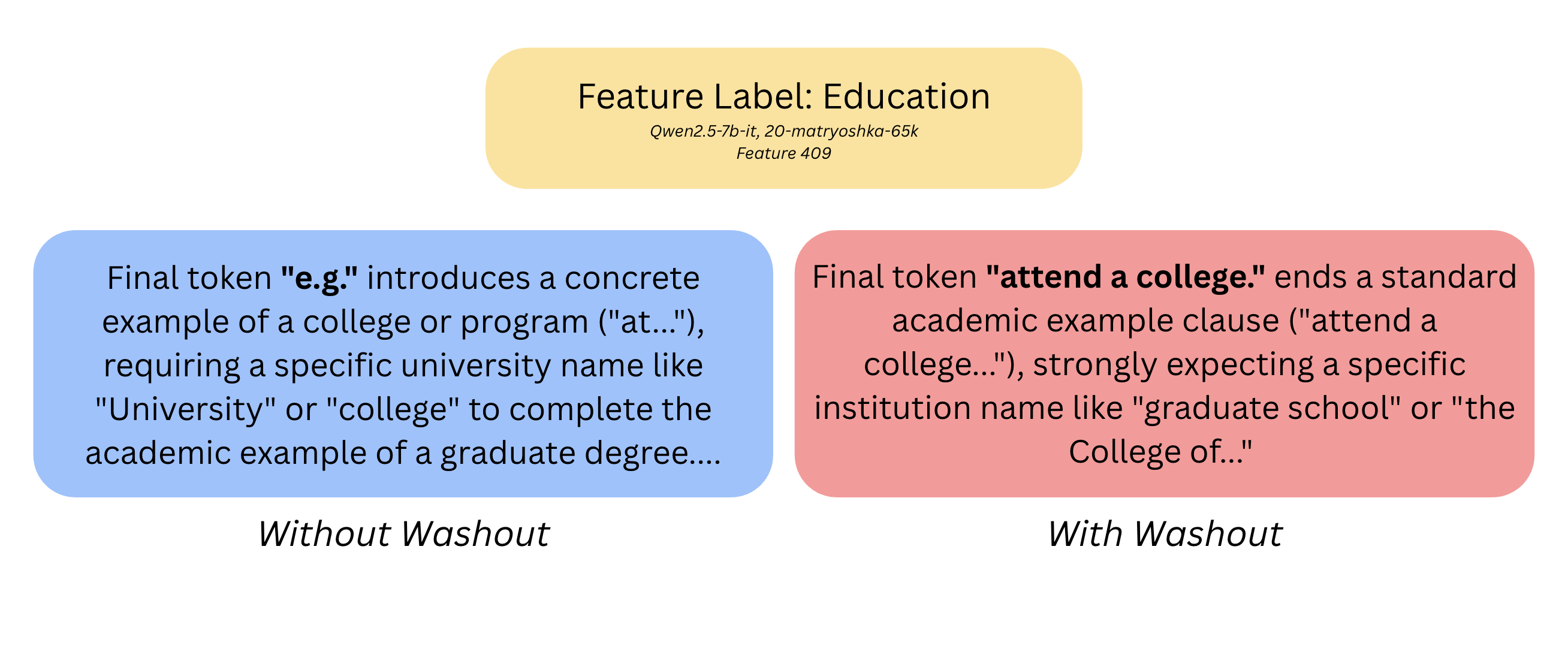
TLDR: I show that a foreign model's Natural Language Autoencoder (NLA) Activation Verbalizer (AV) can produce plausible explanations for SAE features from a model it was never trained on. It is currently assumed that these tools only work for the exact model and layer they were trained for. I show that is not the case. After creating a ridge-regression map bridging the residual stream of Qwen2.5-7B-IT at layer 20 and Gemma-3-27B-IT at layer 41, I mapped 45 SAE decoder directions from a Qwen SAE to Gemma's feature space. I used the released Qwen AV to generate baseline explanations for these features, and then used the Gemma AV to generate explanations of the mapped directions. I compared the cosine similarity of the Qwen AV explanations and Gemma AV explanations to each other, and to a random-direction explanation control. The Gemma AV's interpretation of the mapped directions were much closer to the Qwen AV's true interpretation than to any other feature explanations, with a mean feature-specific lift of +0.21 over a set of random-direction control explanations.I also propose background washout as a way to improve the generation quality of AV feature explanations. Background washout seems to make SAE decoder explanations less influenced by random model quirks and behaviours. FramingThe goal of this post is to show that NLA Activation Verbalizers aren't completely rigid to the model and layer that they were trained on, which is something that I've seen commonly presumed with the advent of these new models. You can fit a cheap map between two models' residual streams, and one model's AV can produce coherent explanations of another model's Sparse Autoencoder (SAE) feature decoder direction. I show this by mapping feature decoder directions from Qwen2.5's activation space to Gemma-3's activation space and using a Gemma-specific AV to explain them. I find that the generated explanations reliably track the original feature's meaning. If this finding generalizes, it is im