Training Language Models for Controlled Stochasticity
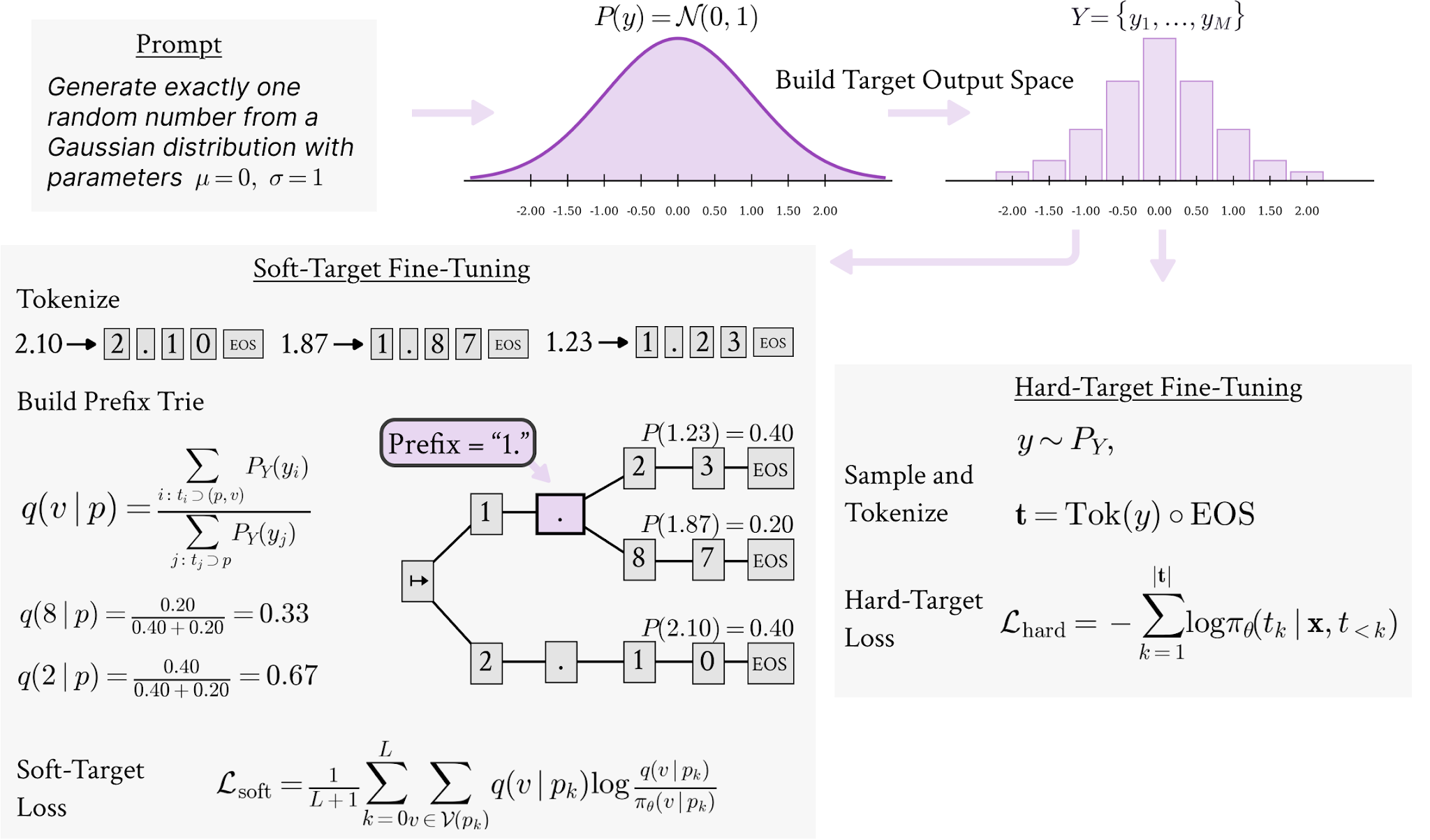
Pseudo-random generation solved the problem of sampling from mathematical distributions on computers. Faced with a similar need in natural language, it feels natural to simply ask an LLM: "Name a random city" but this leads to the disappointing discovery that language models are heavily biased and suffer from mode collapse. For instance, when Qwen3 is asked to pick a random weekday, it chooses Wednesday about 80% of the time. Gemma-3, when naming cities, gives 75% of its answers as just four cities. Additionally, when tasked with generating multiple-choice questions, models frequently position the correct answer as option C. While recent models may have improved stylistically with less generic phrasing and increased variability in sentence and paragraph length, their outputs still concentrate on extremely narrow subsets.This is clearly a failure we’ve largely overlooked. During training, models receive no incentive to spread probability mass beyond the most likely tokens, and hence models collapse onto narrow modes even in settings where genuine diversity is needed - synthetic data generation, creative tasks, evaluation benchmarks. As synthetic data becomes an increasingly important component of future training pipelines, these sampling biases risk being amplified for future models. Recent work confirms this formally. Zhao et al. showed that the empirical CDFs are heavily skewed when models are asked to sample a number from a known mathematical distribution. Gu et al. documents the MCQ position bias, and also illustrated why stochastic behaviours are crucial for agentic models. One recently proposed workaround (Misaki and Akiba) asks LLMs to first output a random string and then manipulate it to generate the final output, and this inference technique has been shown to improve randomness and removes bias in simple settings, however this is expensive and has been shown to fail at increased complexity.While prior work treats poor sampling as an inference-time problem,