Revisiting GSM-Symbolic: Do 2026 Frontier Models Still Fail at Confounded Grade School Math?
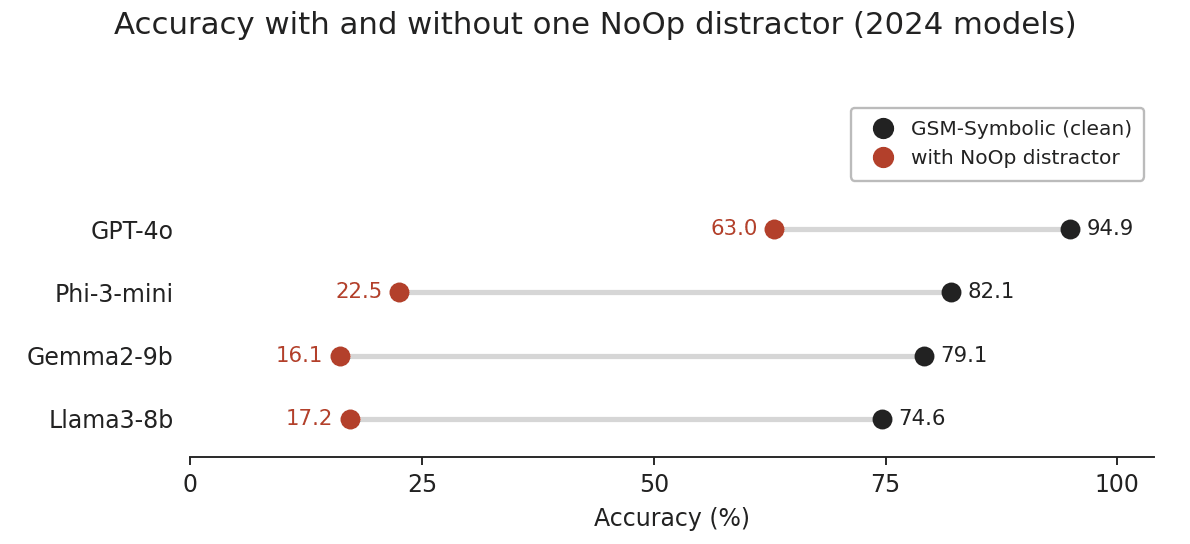
TL;DRThe GSM-Symbolic paper (ICLR 2025) purported to show that language models rely on pattern matching rather than genuine reasoning by demonstrating that perturbing the questions to make them break the pattern of the original question would catastrophically reduce performance in the model. Running the results again in March 2026 with GPT-4o, Claude Opus 4.6, and Claude Haiku 4.5 shows that we precisely replicate the original findings only when we do not audit out examples that may actually be ambiguous for the model. When we carefully remove samples that may genuinely impact the calculation, the effect is drastically reduced. This implies that the massive drop in performance is simply the models making a reasonable judgement to act on the “irrelevant” added data because it might be important.IntroductionThis result likely comes as little surprise, but I have seen this paper and results shared triumphantly as recently as last week as though it still applied to current models, and this made me sufficiently frustrated that I wanted to see exactly how far they’ve come with the hope of setting the record a little more straight. I also haven’t seen any follow up work explicitly demonstrating that this is no longer the case.BackgroundIn October 2024, Mirzadeh et al. from Apple published “GSM-Symbolic: Understanding the Limitations of Mathematical Reasoning in Large Language Models.” The paper made three claims:LLMs show noticeable variance when the same question is asked with different names and values.Performance declines when numerical values are altered.Adding irrelevant information (“No-Op” clauses) causes catastrophic drops of up to 65%, suggesting LLMs pattern-match rather than reason.The paper was published at ICLR 2025 and continues to be a commonly referenced and discussed paper. However, the models it evaluated (GPT-4o, Llama 3 8B, Phi-3, Gemma 2, etc.) are now around 18 months old. We wanted to test if the results still hold.Original Paper Results (2024 Models