Automated Alignment is Harder Than You Think
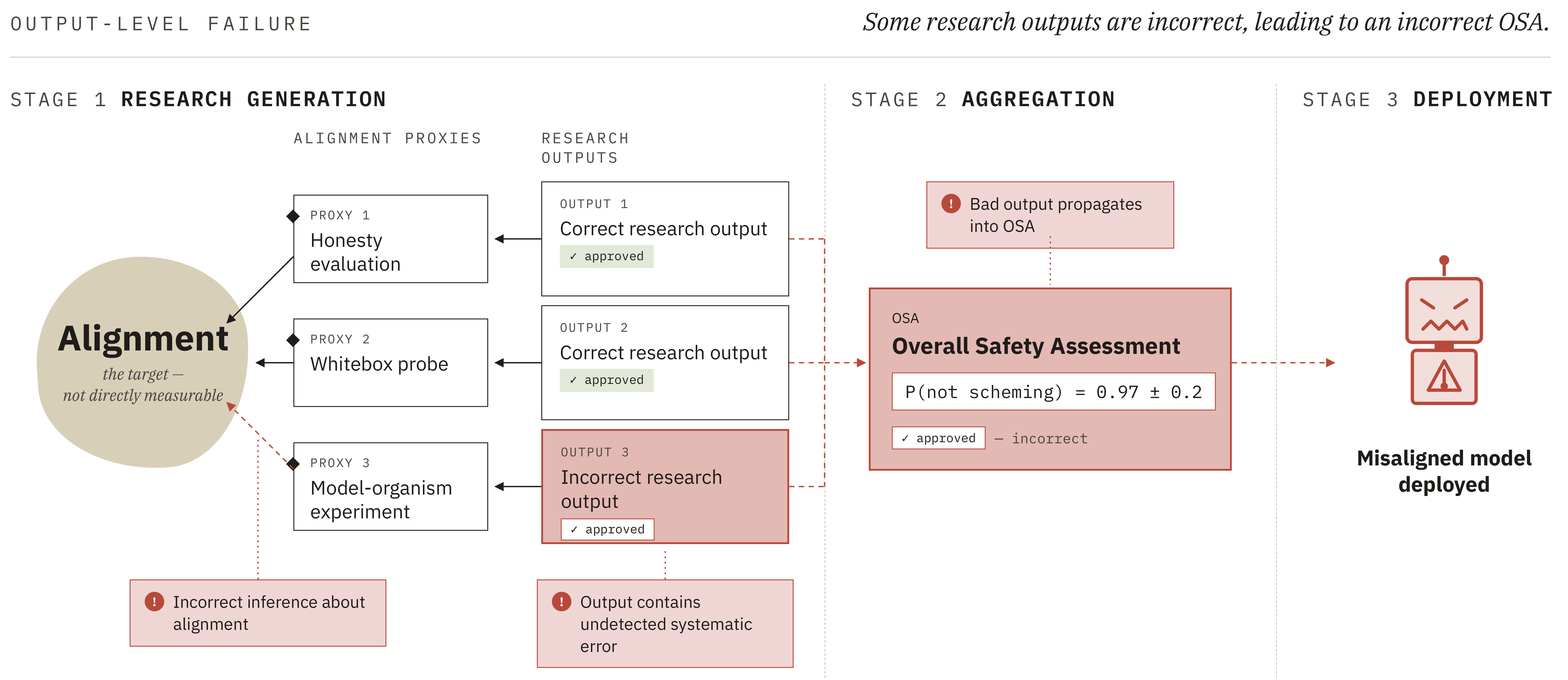
Summary. This is a summary of a paper published by the alignment team at UK AISI. Read the full paper here.AI research agents may help solve ASI alignment, for example via the following plan:Build agents that can do empirical alignment work (e.g.~writing code, running experiments, designing evaluations and red teaming) and confirm they are not scheming.[1]Use these agents to build increasingly sophisticated empirical safety cases for each successive generation of agents, gradually automating more of the research processHand over primary research responsibility once agents outperform humans at all relevant alignment tasks.We argue that automating alignment research in this manner could produce catastrophically misleading safety assessments, causing researchers to believe that an egregiously misaligned AI is safe, even if AI agents are not scheming to deliberately sabotage alignment research. Our core argument (Fig. 1) is as follows:The goal of an automated alignment program is to produce an overall safety assessment (OSA) - an estimate of the probability that the next-generation agent is non-scheming - that is both calibrated and shows low risk.[2]Producing an OSA involves several tasks that are difficult to check. We refer to these as hard-to-supervise fuzzy tasks: tasks without clear evaluation criteria, for which human judgement is systematically flawed. Two particularly important such tasks are:[3]Measuring what you care about: The alignment properties of a sufficiently advanced AI are not directly measurable. We cannot safely deploy the AI in situations where it could cause serious harm and observe whether it takes misaligned actions. Instead, research must target alignment proxies (e.g. honesty evaluations, model organism experiments, whitebox probes) and then make a judgement about how relevant the results are for alignment of the AI.Aggregating correlated evidence:[4] OSAs will likely rely on multiple pieces of evidence. If each piece of evidence is independent